Vous en avez marre de taper les mêmes commandes tous les jours pour réaliser une opération quelconque qui pourrait très bien se passer de vous? Marre d’être esclave de la machine alors cela devrait être le contraire? Dans cette série d’articles consacrée aux scripts shell, nous mettons au travail nos neurones pour déléguer une partie (la moins intéressante) de nos tâches afin de rendre notre quotidien plus intéressant.
Dans l’article précédent, nous avons vu comment créer notre premier script shell, le rendre exécutable et enfin comme lui faire prendre en compte des arguments. Dans cet article, nous allons parler des variables.
Avant d’aller plus loin, si vous ne savez pas qu’est une variable ou que vous souhaitez en savoir plus, je vous invite à lire cet article d’initiation à la programmation consacré aux variables.
Les variables
En shell une variable se défini comme suit:
variable=valeur
variable est le mot qui, à chaque appel précédé d’un dollar $, vous permettra d’accéder à la valeur. En shell, une variable peut contenir les données ci-dessous:
# Le résultat d'une commande (liste ou chaîne de caractères)
resultats=`commande`
# Une liste, qui, traité par la structure de contrôle adaptée se comportera un peu comme une variable tableau
# Chaque élément de la liste est séparé de l'autre par un espace
liste="elem1 elem2 elem3 elem4 elem5 elem6"
# Une valeur numérique
nombre=123
# Une chaîne de caractère
chaine="blablabla"
# La valeur d'une autre variable (ne pas oublier de placer un dollar <strong>$</strong> devant le nom de la variable appelée)
# Ici copie contiendra la liste de valeurs "elem1 elem2 elem3 elem4 elem5 elem6"
copie=$listeLes variables d’environnement
Les variables d’environnement sont propres à chaque système d’exploitation. Elles sont en général définies dans des scripts au démarrage du système et seront indispensables bon fonctionnement de ce dernier. A chaque lancement de terminal ou d’un script shell, les variables d’environnement seront chargées à partir de scripts existants. (/home/user/.bashrc, /home/user/.profile, /etc/environment)
Voici quelque exemples de variables d’environnement (la commande printenv permet d’afficher les variables d’environnement):
- PATH : Chemin de recherche pour les commandes (à la saisie d’une commande, le shell partira à sa recherche dans les chemins définis)
- SHELL : Contient le chemin vers l’interpréteur de commandes utilisé.
- SSH_TTY : Chemin vers le numéro de terminal utilisé
- HOME : Dossier utilisateur (home directory)
Pour définir une variable d’environnement, il suffit de saisir la commande export NomVariable (où NomVariable est à remplacer par le nom de votre variable).
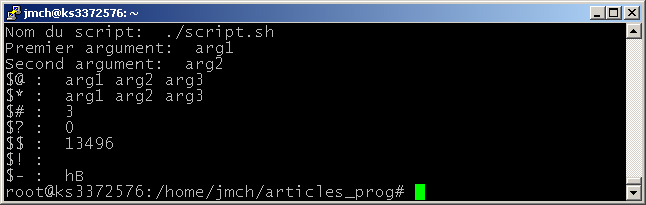
Les variables spéciales
Comme dans la plupart des système de programmation, il existe un certain nombre de variables spéciales qui sont prédéfinies.
- $@ : Liste des paramètres (séparés par des espaces) passés au script lors de son exécution
- $* : Liste des paramètres (séparés par le caractère défini dans la variable spéciale IFS) passés au script lors de son exécution (dépend de l’interpréteur utilisé)
- $# : Affiche le nombre de paramètres passés au script lors de son exécution
- $? : Contient le code retour de la dernière commande exécutée. Permet de contrôler le déroulement d’une commande afin de réaliser des traitements conditionnels
- $$ : Contient le numéro du processus du script en cours d’exécution. Programmes ou scripts, chaque processus possède un numéro unique pour l’identifier (voir commande ps)
Bien entendu il existe d’autres variables prédéfinie mais elles sont réservées à des utilisations spécifiques que nous ne verrons pas dans cet article. Ici nous parlons du shell en général (sh), mais certains shell très aboutis comme BASH possèdent de nombreuses variables spéciales et permettent de réaliser des opérations complexes sur les variables (découpage et traitement des mots).
Quelques exemples
Stocker le résultat d’une commande dans une variable
# Resu va contenir le résultat de la commande ls /tmp
resu=`ls /tmp`
# On appelle le contenu de la variable avec la commande echo et en précédant son nom d'un dollar <strong>$</strong>
echo $resu
# Le résultat affiché devrait ressembler à quelque chose comme ça (une liste dont chaque élément est séparé par un espace)
hsperfdata_root lost+found mc-root wsdl-jmch-c392d33ea3aa33c8796f5613216f2edbEnrichir une variable existante
#Ajoute un dossier au PATH (chemin de recherche pour l'éxécution des commandes)
PATH=$PATH:/home/dir/bin
# Affiche le résultat
echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/home/dir/binRécupérer le code retour d’une commande
# Effectue une recherche de motClé dans tous les fichiers contenu dans /var/www/dossier
grep -r "motClé" /var/www/dossier
# Stocke le code retour de la commande dans la variable ctrl
ctrl=$?
# Affiche le code retour
echo "Le code retour de la commande grep est : " $ctrlSubstitutions
Certains traitement spéciaux permettent de découper ou remplacer le contenu des variables selon certaines conditions. Cela s’appelle la substitution. Une fois encore, certains interpréteur plus évolués permettrons des substitutions bien plus pratiques et nombreuses.
# Définition du contenu de la variable toto
toto="machin"
# Affiche le contenu de la variable toto
echo ${toto} # Affiche : machin
# Contenu de substitution si la variable titi est nulle (non définie). Ce qui est le cas ici présent
# Le contenu de la variable n'est pas affecté, c'est seulement une valeur de remplacement qui sera utilisé pour cet affichage
echo ${titi:-autrechose} # Affiche : autrechose
# Contenu de substitution si la variable titi est nulle (non définie). Ce qui est le cas ici présent
# Cette fois le contenu de la variable est remplacé
echo ${titi:=autrechose} # Affiche : autrechose
# Affiche un message sur la sortie d'erreur standard (stderr) si la variable n'est pas définie
toto={$titi:?Valeur absente} # Affiche : Valeur absente
# Contenu de substitution si la variable titi existe (contenu défini)
# N'affecte pas le contenu de la variable, il s'agit d'une valeur de remplacement utilisée pour cet affichage
echo ${titi:+remplacement} # Affiche : remplacement
# Découpage du contenu par caractère
# Au préalable on définit la valeur de titi avec un texte long
titi="total 4 -rw-r--r-- 1 jmch jmch 1749 Jun 29 02:44 out.txt"
# On commence l'affichage de la variable à partir du caractère n°48
echo ${titi:48} # Affiche : out.txt
# On commence l'affichage de la variable à partir du caractère n°48 et on le limite à 6 caractères seulement
echo ${titi:48:6} # Affiche : out.tNous venons de faire un bref tour des possibilités concernant les variables. Comme dit plus haut, il existe de nombreuses autres possibilités qui vont dépendre de l’interpréteur de commande utilisé. Dans les prochains articles nous allons parler des structures de contrôle qui nous permettront d’analyser des résultats afin de prendre des décision ou encore de traiter des listes de valeurs.