Choisir la souveraineté numérique, sans renoncer à la performance
Catégorie : Programmation
La programmation est au cœur de toute solution numérique performante. Dans cette section, je partage des articles techniques autour du développement web, du code et des bonnes pratiques de programmation. Qu’il s’agisse de PHP, de JavaScript ou encore de frameworks comme CodeIgniter, chaque article vise à éclairer des problématiques concrètes et à proposer des solutions efficaces. Ces contenus s’adressent aussi bien aux développeurs curieux qu’aux professionnels cherchant à optimiser leurs projets applicatifs.
Vous retrouverez les liens et références à la fin de cet article.
1 – Les bits
Le bit est la plus petite unité numérique définissable. Le bit correspond l’état d’un signal électrique (arrêt ou marche). Un bit peut se résumer à un interrupteur contrôlant une ampoule qui est soit en à l’arrêt (0) soit en fonctionnement (1). Seul, il ne représente rien et on ne peut pas définir de donnée plus complexe que OUI ou NON. Pour créer l’informatique il aura été nécessaire de regrouper les bits en blocs nommés octets.
Représentation d’une séquence de bits sous forme de signal électrique La ligne horizontale représente le temps, et la ligne vertical l’état du signal
2 – Les octets
Stockage des octets
Sur les premiers systèmes d’exploitations publics (GECOS créé en 1962 par la General Electric) les octets étaient des assemblages de 6 bits stockés sur des fiches en carton appelées “cartes perforées” et regroupés par “mots” de 36 bits. La première carte perforée a été créée vers 1725 pour automatiser des métiers à tisser.
Plus tard, avec l’apparition du standard ASCII, les octets sont devenus des assemblages de 8 bits.
Un bit pouvant avoir 2 valeurs (0 ou 1), un octet comportant 8 bits permet donc de coder 28 = 2×2×2×2×2×2×2×2 = 256 valeurs (de 0 à 255).
Un octet peut être représenté de différentes manières:
En binaire allant de 00000000 à 11111111
En hexadécimal (base 16) de 00 à FF (aussi écrit: 0x00 à 0xFF)
En décimal non signé de 0 à 255
En décimal signé de -128 à 127
Voici une liste de supports pour stocker nos octets:
Sur des cartes perforées par “mots” de 80 caractères de 8 bits (mais aussi les codes bar ou QR codes)
Sur des puces électroniques PROM – EPROM – EEPROM (cartes SD, ou disques SSD, barettes de mémoire RAM)
Sur des bandes magnétiques, cassettes ou cartouches, puis disquettes (cartouches LTO, cassettes DAT, et aussi sur nos veilles cassettes audio à l’époque des Amstrad et ORIC)
Ces données stockées sous forme de signaux électriques étaient décodées par des modem intégrés à nos vieux ordinateurs
Sur des disques de métal au format binaire proche des cartes perforées (CDROM, DVDROM, BluRay)
Sur des disques magnétiques au format binaire par impulsions électriques (disques dur)
A présent que nous avons défini les octets, nous savons les stocker sur différents types de supports. C’est bien beau tout ça, mais qu’allons nous faire de ces données numériques?
Traitement des octets
Les microprocesseurs ont évolué depuis l’aube de l’informatique et leur aptitude à traiter des mots de plus en plus long et de plus en plus rapidement ont permis aux ordinateurs d’évoluer jusqu’aux capacités époustouflantes qu’on leur connait aujourd’hui. Mais cela n’a pas toujours été ainsi. Aux premières heures de l’informatique grand public, les microprocesseurs ne savaient traiter qu’un nombre de données restreint et pire encore, ils le faisaient beaucoup plus lentement qu’aujourd’hui.
Voici l’évolution de la taille des mots traités par les microprocesseurs (CPU) grand public:
La taille des mots en bits qu’un microprocesseur sait traiter lui permet également de définir des plages d’adresses pour stocker des données en mémoire. Il faut se représenter la mémoire RAM comme un damier avec des coordonnées pour chaque case. Plus le damier est grand, plus vous aurez un nombre de case important et donc vous aurez besoin plus de bits pour définir ce nombre. Si vous rangez vos données dans le damier mais que vous n’êtes pas en mesure de noter les coordonnées où elles sont stockées, comment allez vous les retrouver?
Voici la quantité de mémoire adressable en fonction de la taille du bus mémoire en bits:
8 bits ⇒ 16 Ko (2 puissance 8)
16 bits ⇒ 64 Ko (2 puissance 16)
32 bits ⇒ 4 Go (2 puissance 32)
64 bits ⇒ 16 777 216 To ou 16 Eo (2 puissance 64)
Bien sûr, il existe des astuces de programmation qui permettent d’adresser plus de mémoire que la limite du bus ne le permet. Mais ce sera au détriment des performances.
3 – Les types de données de base
Maintenant, avec les connaissances que nous avons, nous savons traiter et stocker des données…
Oui mais au fait, quoi comme données???
C’est vrai! Comment faire la différence entre des numéros de série et des vraies données numériques utilisées dans des calculs?
En somme, comment différencier des chiffres utilisés dans du texte et des chiffres utilisés pour des calculs? Comment faire comprendre ça à un microprocesseur?
Le standard ASCII nous indique que chaque caractères imprimables (a, B, c, D, 0, 1, 2, @ etc…) correspond à un code (dit code ASCII) numérique lui donnant une position bien définie dans la table du même nom. Ainsi, avec seulement des chiffres, nous sommes capables de stocker du texte et bien d’autres choses encore.
Par exemple: Le nombre 32768 stocké sous forme de caractères nous coûterait 5 caractères ⇒ 6|5|5|3|5 soit en hexadécimal 33 32 37 36 38.
Le même nombre stocké avec un type binaire adapté (short int par exemple) ne coûterait que 2 caractères ⇒ 80 00
Il existe plusieurs types de données en fonction de l’usage qui leur sera réservé (affichage ou calcul, petits nombres ou très grands nombres, nombres à virgule flottante)
Les types de données présentées ci-dessous sont les types de base tels qu’ils sont utilisés par les microprocesseurs (en langage C, les noms changent en fonction des langages, mais le contenu et le stockage restent les mêmes).
(signed) char
Type de donnée: Caractère (character) / Entier signé de faible valeur
Taille: 1 octet (8 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(char)
Une chaîne de caractère est en fait un tableau de caractères comme suit: nombre de caractères × sizeof(char)
Peut contenir: ‘a’ ou ‘z’ ou ‘8’ ou ‘+’
Valeur décimale: de -128 à 127
Valeur hexadécimale: de 00 à FF
Stockage: Non affecté
unsigned char
Type de donnée: Caractère (character) non signé / Entier de faible valeur positive
Taille: 1 octet (8 bits) / caractère en général (ASCII)
En C il est recommandé de calculer la taille avec la fonction sizeof(char)
Peut contenir: ‘a’ ou ‘z’ ou ‘8’ ou ‘+’
Valeur décimale: de 0 à 255
Valeur hexadécimale: de 00 à FF
Stockage: Non affecté
(signed) short int
Type de donnée: Entier numérique
Taille: 2 octets (16 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(short int)
Peut contenir: de -32768 à 32767
Valeur décimale: de 0 à 65535
Valeur hexadécimale: de 00 00 à FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
unsigned short int
Type de donnée: Entier numérique positif
Taille: 2 octets (16 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(short int)
Peut contenir: de 0 à 65535
Valeur décimale: de 0 à 65535
Valeur hexadécimale: de 00 00 à FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
(signed) int (16 bits/32 bits)
Type de donnée: Entier numérique
Taille: 2 octets (16 bits) / 4 octets (32 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(int)
Peut contenir: de -2 147 483 648 à 2 147 483 647
Valeur décimale: de 0 à 4 294 967 295
Valeur hexadécimale: de 00 00 00 00 à FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
unsigned int (16 bits/32 bits)
Type de donnée: Entier numérique positif
Taille: 2 octets (16 bits) / 4 octets (32 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(int)
Peut contenir: de 0 à 4 294 967 295
Valeur décimale: de 0 à 4 294 967 295
Valeur hexadécimale: de 00 00 00 00 à FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
(signed) long int (16 bits/32 bits)
Type de donnée: Entier numérique
Taille: 4 octets (32 bits) / 8 octets (64 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(long int)
Peut contenir: de -9 223 372 036 854 775 808 à -9 223 372 036 854 775 807
Valeur décimale: de 0 à 18 446 744 073 709 551 615
Valeur hexadécimale: de 00 00 00 00 00 00 00 00 à FF FF FF FF FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
unsigned lont int (16 bits/32 bits)
Type de donnée: Entier numérique positif
Taille: 4 octets (32 bits) / 8 octets (64 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(long int)
Peut contenir: de 0 à 18 446 744 073 709 551 615
Valeur décimale: de 0 à 18 446 744 073 709 551 615
Valeur hexadécimale: de 00 00 00 00 00 00 00 00 à FF FF FF FF FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
(signed) long long int
Type de donnée: Entier numérique de grande taille
Taille: 8 octets (64 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(long long int)
Peut contenir: de -9 223 372 036 854 775 808 à -9 223 372 036 854 775 807
Valeur décimale: de 0 à 18 446 744 073 709 551 615
Valeur hexadécimale: de 00 00 00 00 00 00 00 00 à FF FF FF FF FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
unsigned long long int
Type de donnée: Entier numérique positif de grande taille
Taille: 8 octets (64 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(long long int)
Peut contenir: de 0 à 18 446 744 073 709 551 615
Valeur décimale: de 0 à 18 446 744 073 709 551 615
Valeur hexadécimale: de 00 00 00 00 00 00 00 00 à FF FF FF FF FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
float
Type de donnée: Flottant numérique à précision simple
Taille: 4 octets (32 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(float)
Peut contenir: de -3.4e-38 à 3.4e38 avec une précision à 7 décimales
Valeur décimale: de 0 à 4 294 967 295
Valeur hexadécimale: de 00 00 00 00 à FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
double
Type de donnée: Flottant numérique à précision double
Taille: 8 octets (64 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(double)
Peut contenir: de -1.7e-308 à 1.7e308 avec une précision à 15 décimales
Valeur décimale: de 0 à 18 446 744 073 709 551 615
Valeur hexadécimale: de 00 00 00 00 00 00 00 00 à FF FF FF FF FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
long double (32 bits / 64 bits)
Type de donnée: Flottant numérique de grande taille à forte précision
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
void * (dépendant de l’architecture)
Type de donnée: Pointeur (adresse mémoire)
Taille: (complètement dépendant de l’architecture)
En C il est recommandé de calculer la taille avec la fonction sizeof(void *)
Peut contenir: Toute la plage adressable par l’architecture
Valeur décimale: (complètement dépendant de l’architecture)
Valeur hexadécimale: (complètement dépendant de l’architecture)
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
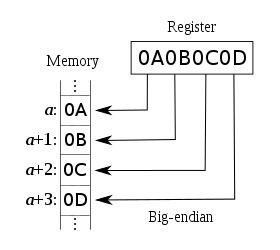
4 – L’histoire du petit et du grand indien…
Il existe différents ordres de stockage des données numérique de grande taille (16 bits et au delà) dont les plus connus sont nommés LITTLE ENDIAN, BIG ENDIAN ou encore BI-ENDIAN (plus rare). Pour des raisons de culture, de conception et de logique différentes, les deux principales architectures stockent et traitent les données dans un ordre qui lui est propre.
Processeurs LITTLE-ENDIAN: Intel et compatibles Intel (x86 IA32, IA64 ou amd64)
Le petit boutiste (LITTLE-ENDIAN) range l’octet de poid faible à l’adresse la plus petite
Processeurs BIG-ENDIAN: SPARC, ARM, PowerPC
Le grand boutiste (BIG-ENDIAN) range l’octet de poid fort à l’adresse la plus petite
En résumé, on peut dire que les données sont rangées en mémoire en fonction de l’architecture matérielle qui les traite.
Vous trouverez ci-dessous un petit bout de code en C qui, une fois compilé (avec gcc) et éxécuté, va générer un fichier par type (au sens C du terme) en stockant une valeur à l’intérieur afin de vous donner un aperçu de la manière dont les données numériques sont rangées en mémoire. Le binaire enregistre les données dans des fichiers telles qu’elles sont stockées en mémoire. Je vous recommande de vous équiper d’un éditeur hexadécimal pour comparer les contenus des fichiers (Editeur hexadécimal).
#include<stdio.h>#include<stdlib.h>/* Pour compiler ce code source:* gcc sizeof-types.c -o sizeof-types* Pour éxécuter ce programme une fois compilé* ./sizeof-types (sous UNIX/Linux)* ou* sizeof-types.exe (sous Windows)*/intmain(void) {FILE*fd;charchar_val='c';shortintsint_val=25315;intint_val=-1123315;longintlint_val=-3223372036854775807L;floatfloat_val=3.1415926F;doubledouble_val=3.14159265358979323846264338;void*void_val=(void* ) &int_val;/* Codes couleur pour affichage */charbtitle[]="\033[04;34;43m";charecol[]="\033[0m";charbnom[]="\033[04;33;40m";charbtaille[]="\033[01;33;40m";printf("%sType\t\tTaille\t\tType C%s\n",btitle,ecol);printf("%sEntier court\t%s%d octets\t%sshort int%s\n",bnom,ecol,sizeof(shortint),btaille,ecol);printf("%sEntier\t\t%s%d octets\t%sint%s\n",bnom,ecol,sizeof(int),btaille,ecol);printf("%sEntier long\t%s%d octets\t%slong int%s\n",bnom,ecol,sizeof(longint),btaille,ecol);printf("%sEntier long long\t%s%d octets\t%slong long int%s\n",bnom,ecol,sizeof(longlongint),btaille,ecol);printf("%sFlottant\t%s%d octets\t%sfloat%s\n",bnom,ecol,sizeof(float),btaille,ecol);printf("%sCaractere\t%s%d octets\t%schar%s\n",bnom,ecol,sizeof(char),btaille,ecol);printf("%sSans type\t%s%d octets\t%svoid%s\n",bnom,ecol,sizeof(void),btaille,ecol);printf("%sDouble\t\t%s%d octets\t%sdouble%s\n",bnom,ecol,sizeof(double),btaille,ecol);printf("%sDouble long\t%s%d octets\t%slong double%s\n",bnom,ecol,sizeof(longdouble),btaille,ecol);printf("%sPointeur\t%s%d octets\t%svoid *%s\n",bnom,ecol,sizeof(void*),btaille,ecol);/* Ecriture de données typées sur le disque *//* Lire les fichiers avec un éditeur hexadécimal *//* char */fd=fopen("./char","w");if (fd) {fwrite(&char_val,sizeof(char), (size_t) 1,fd);printf("Le caractère (char) 'c' est écrit dans le fichier './char'\n");fclose(fd);}/* short int */fd=fopen("./short_int","w");if (fd) {fwrite(&sint_val,sizeof(shortint), (size_t) 1,fd);printf("La valeur (short int) 25315 est écrite dans le fichier './short_int'\n");fclose(fd);}/* int */fd=fopen("./int","w");if (fd) {fwrite(&int_val,sizeof(int), (size_t) 1,fd);printf("La valeur (int) -1 123 315 est écrite dans le fichier './int'\n");fclose(fd);}/* long int */fd=fopen("./long_int","w");if (fd) {fwrite(&lint_val,sizeof(longint), (size_t) 1,fd);printf("La valeur (long int) -3 223 372 036 854 775 807 est écrite dans le fichier './long_int'\n");fclose(fd);}/* float */fd=fopen("./float","w");if (fd) {fwrite(&float_val,sizeof(float), (size_t) 1,fd);printf("La valeur (float) 3.1415926 est écrite dans le fichier './float'\n");fclose(fd);}/* double */fd=fopen("./double","w");if (fd) {fwrite(&double_val,sizeof(double), (size_t) 1,fd);printf("La valeur (double) 3.14159265358979323846264338 est écrite dans le fichier './double'\n");fclose(fd);}/* void * */fd=fopen("./void","w");if (fd) {fwrite(&void_val,sizeof(void*), (size_t) 1,fd);printf("Le pointeur (void *) %p est écrit dans le fichier './pointer'\n", (void*) void_val);fclose(fd);}returnEXIT_SUCCESS;}
J’ai exécuté ce code sur mon PC actuel (CPU Intel Quad Core 64 Bits) ainsi que sur ma vieille station SUN Ultra Sparc 64 bits elle aussi et je vous ai préparé un petit tableau ci-dessous avec les résultats à comparer. La différence saute aux yeux dès que l’on arrive sur des types plus complexes qu’un simple caractère.
Type de base
Valeur
LITTLE-ENDIAN (mon PC)
BIG-ENDIAN (ma vieille station Sun Ultra SPARC 64)
char (8 bits / 1 octet)
c
63
63
short int (16 bits)
25315
E3 62
62 E3
int (32 bits)
-1123315
0D DC EE FF
FF EE DC 0D
float (32 bits)
3.1415926
DA 0F 49 40
40 49 0F DA
long int (64 bits)
-3223372036854775807
01 00 58 EC 35 48 44 D3
D3 44 48 35 EC 58 00 01
double (64 bits)
PI (26 décimales)
40 09 21 FB 54 44 2D 18
18 2D 44 54 FB 21 09 40
Liens et références
Cet article n’a pas pour vocation d’être complet. Si vous souhaitez en savoir plus, voici une liste d’articles traitant en détails des différents sujets soulevés dans cet article. Bonne lecture!
Pour offrir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations des appareils. Le fait de consentir à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou les ID uniques sur ce site. Le fait de ne pas consentir ou de retirer son consentement peut avoir un effet négatif sur certaines caractéristiques et fonctions.
Fonctionnel
Toujours activé
L’accès ou le stockage technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
L’accès ou le stockage technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’internaute.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
L’accès ou le stockage technique est nécessaire pour créer des profils d’internautes afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.