Cet article a pour vocation de décrire brièvement et simplement les différents types de téléphonies utilisées aujourd’hui. il ne se revendique en aucun cas d’être complet.
Le Réseau Téléphonique Commuté (RTC)
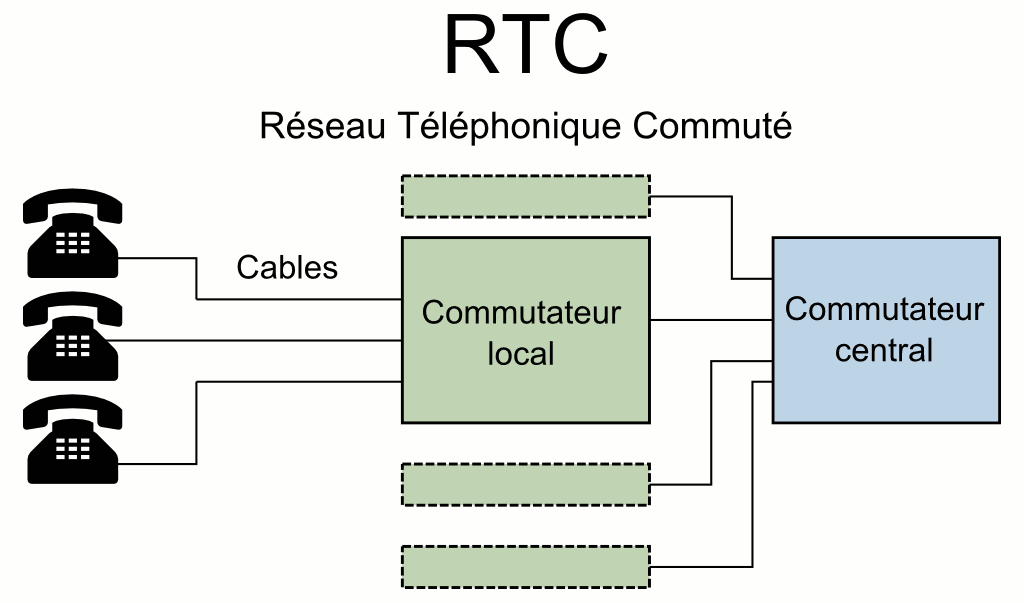
C’est le plus vieux système de téléphonie utilisé en France. Toujours existant, et bien qu’ayant évolué depuis sa création, ce dernier fonctionne de manière assez simple. Un mécanisme associé à des composants électroniques simples envoient des impulsions électriques à un commutateur, lui indiquant le numéro de votre destinataire. Les commutateurs reliés entre eux, déterminent et ferment les circuits nécessaires pour vous mettre en lien avec votre correspondant. Pour le reste, un simple système de micro et d’écouteur se chargent d’enregistrer et restituer la voix au travers d’une paire de fils de cuivre. Des filtres électroniques et un système de modulation de fréquence permettent de faire passer plusieurs conversations en simultané sur une même ligne physique. Au départ, un lien électrique existait entre les deux correspondants. Les systèmes ayant été informatisés depuis, ce n’est plus le cas désormais.



Pour téléphoner via le Réseau Téléphonique Commuté, il faut généralement utiliser un téléphone fixe (à cadran ou à touches) équipé d’une prise gigogne mais aussi avoir un abonnement chez l’opérateur français historique, Orange (anciennement France Télécom).
Chez Orange, un abonnement au réseau RTC coûte 16.96 €. En France métropolitaine, le raccordement d’une nouvelle ligne téléphonique coûte 55 € + 69 € si le déplacement d’un technicien est nécessaire. (source: Boutique Orange)
Le réseau téléphonique sans fil (GSM)
GSM: Global System for Mobile Communications soit Système Global pour Communications Mobiles
Le développement du réseau GSM à commencé en France durant la seconde moitié des années 80. Les premiers téléphones GSM français datent du début des années 90 mais restent des objets rares et exceptionnels. C’est seulement à la fin des années 90, début des années 2000 que le marché de la téléphonie mobile explose réellement, atteignant en quelques années l’ampleur qu’on lui connaît aujourd’hui.

Pour accéder au réseau GSM, vous devez posséder un téléphone mobile et acheter une carte SIM chez opérateur de téléphonie mobile comme par exemple: Orange, SFR, Bouygues. Son fonctionnement est plus complexe que celui de la téléphonie RTC. Ici le téléphone mobile est une véritable prouesse de composants électroniques avancés, alliant performances et faible consommation. Votre voix est échantillonnée afin d’être numérisée puis compressée avant d’être envoyée sous la forme de signaux radio haute fréquence à l’antenne relais la plus proche qui se chargera au choix de renvoyer ce signal vers une autre antenne relais dans le cas d’une communication de mobile à mobile, soit de relayer via un commutateur les données décodées dans le cas d’une communication mobile vers fixe.
En moyenne les tarifs d’un abonnement mensuel vont de 2 € à 70 € pour le particulier. Pour plus de détails, vous pouvez utiliser des comparateurs de forfait mobile comme il en existe plein sur la toile.
Téléphoner via INTERNET (VoIP et SIP)
VoIP: Voice on IP ou voix sur IP. Correspond au principe de véhiculer du son (votre voix, celle de votre correspondant) au travers du réseau informatique utilisé sur internet soit TCP/IP.
SIP: Session Initiation Protocol ou Protocole d’Initiation de Session. Protocole ouvert, normalisé et standardisé utilisé dans les communication téléphoniques ou visiophoniques.
Ce système de communication s’est développé avec l’avènement de l’internet à la fin des année 90, début des années 2000. Comme pour la téléphonie mobile, votre voix est échantillonnée et numérisée au travers d’un micro et de la carte son de votre ordinateur puis compressée et encodée par un logiciel qui va s’occuper de l’envoyer au logiciel de votre correspondant pour qu’elle y soit décodée puis entendu. Et ceci en temps réel ou presque. Pour les plus connus de ces logiciels, nous pouvons citer Net Meeting de Microsoft, mais aussi Skype et plus récemment Mumble ou encore TeamSpeak.

Pour le prix de votre forfait internet, vous pouvez téléphoner en Australie ou aux Etats-Unis sans vous poser de question sur la durée de vos conversations (sauf si votre accès n’est pas illimité). Toutefois, les communications sur internet ne pouvaient en aucun cas interagir avec les réseaux de téléphonie existant et inversement. C’est alors que sont arrivés les opérateurs SIP qui, dans le courant des années 2000 ont permit le lien entre la VoIP sur Internet et la téléphonie. L’opérateur SIP est en quelque sorte le fil qui relie la téléphonie classique (qu’elle soit analogique via RTC ou numérique) et la VoIP utilisée sur Internet. Ces opérateurs possèdent des numéros de téléphone dans le monde entier et vont vous permettre de les utiliser depuis votre logiciel de téléphonie SIP sur Internet.
Vous vivez en France et vous déciez de louer un numéro de téléphone Australien. Vous pouvez être appelé par tous les Australiens comme si vous étiez un habitant local et sans supplément de forfait. Inversement, vous pouvez téléphoner de partout en Australie au tarif d’un appel local alors que vous habitez en France. Pour résumer, votre opérateur sera le lien entre la communication VoIP sur internet et les réseaux de téléphonies GSM ou RTC.
Dans l’hypothèse inverse, vous êtes en vacances aux USA. Votre numéro SIP français, vous permet d’être appelé par n’importe qui en France au prix d’un appel local et vous pouvez également appeler n’importe qui en France depuis un numéro local sans payer de supplément. De plus, certains opérateurs vous proposent de relayer les messages laissés sur le répondeur de votre téléphone SIP en pièce jointe par e-mail.
Pour accéder à des services de téléphonie SIP, vous devez créer un compte (gratuit pour certains) chez un opérateur SIP comme: IPPI ou encore OVH. D’autres sociétés comme Microsoft et Google proposent des services similaires au travers de leur application respective Skype et Google Talk. Il faut également être équipé au choix, d’un logiciel permettant de se connecter à un opérateur de téléphonie SIP aussi appelé softphone (téléphone logiciel) comme: Ekiga, Zoiper ou encore X-Lite. Vous pouvez également acheter un téléphone physique VoIP ou utiliser votre smartphone comme un softphone une fois celui-ci connecté à internet. Vous pouvez même utiliser votre téléphone fixe ou mobile et appeler en utilisant votre numéro SIP grâce aux options proposées par certains opérateurs!
En moyenne les premiers prix d’un abonnement SIP en France débutent à 1.20 €. Après cela va dépendre du nombre de numéros que vous possédez, dans quels pays vous possédez ces numéros et la quantité d’appels que vous allez passer avec. Bien entendu, ces appels sont totalement gratuits lorsqu’ils restent entre opérateurs SIP et qu’ils transitent par internet. Cela change dès qu’on arrive sur des réseaux physiques. Vous pouvez vous équiper d’un groupe de 10 lignes téléphoniques en VoIP à moindre coût et sans avoir à vous encombrer avec du matériel cher et encombrant comme c’est le cas avec la téléphonie classique d’entreprise.
Certaines offres grand public (triple play avec box) utilisent le système de la téléphonie VoIP. (Free, Numericable…)
En bref…
RTC: Solution de communication analogique basée sur un réseau filaire. Relativement chère et limitée à la position géographique de votre ligne.
GSM: Solution de communication numérique basée sur un réseau sans fil. Peu cher et permet de se déplacer de partout. Prévoir des surcoûts pour les communications depuis l’étranger.
VoIP: Solution de communication numérique basée sur un réseau informatique et à travers internet. Peut être gratuit entre deux postes sur internet, le coût reste faible même sur des appels hors internet. Permet d’être joignable et de téléphoner depuis n’importe où pourvu d’avoir accès à internet. Vous pouvez téléphoner sans avoir besoin de posséder un téléphone physique et sans contrainte géographique.
Ressources et liens
- Article Wikipédia sur le réseau RTC
- Article Wikipédia sur le réseau GSM
- Article Wikipédia sur le traitement du signal et l’échantillonnage
- Article Wikipédia sur la VoIP
- http://www.frameip.com/voip
- Logiciel de VoIP Mumble
- Logiciel de VoIP TeamSpeak
- Opérateur de téléphonie OVH
- Opérateur de téléphonie IPPI
- Article Amazon: Téléphone VoIP Physique
- Icones Glyphicons utilisés pour illustrer cet article