Les gens me demandent souvent ce qu’est un site responsive, à quoi cela sert, si il n’est pas préférable de faire l’acquisition d’une version mobile ou tablette ou si une application mobile ne sera pas plus efficace. Ce n’est pas facile de donner une réponse succincte car en vérité cela va dépendre de certains paramètres comme les attentes du client par rapport à son site web, mais également son budget et la clientèle ciblée.
Qu’est ce que responsive veut dire?
Un site web responsive signifie que la disposition du contenu va s’adapter à la taille de votre écran (mobiles, tablettes, petits écrans) afin d’optimiser la lecture. Il peut être confortable de naviguer sur un site lorsque vous avez un ordinateur de bureau avec un énorme écran. Cette expérience change radicalement lorsque vous vous retrouvez sur des écrans bien plus petit lorsque vous êtes en déplacement par exemple.
Voici quelques petits schémas pour illustrer mes propos :
Un site web affiché sur un écran de bureau moderne avec une bannière, des éléments de menu, des images et des articles
Le même site affiché sur un écran de téléphone mobile beaucoup plus petit
Dans l’exemple ci-dessus, nous perdons clairement en lisibilité. En effet pour naviguer sur le site, il est nécessaire de zoomer sur l’écran tactile puis de se déplacer pour lire et viser le bouton ou le lien sur lequel vous souhaitez cliquer ce qui demande une certaine gymnastique et est au final peu pratique. Imaginez maintenant ce que cela peut donner sur un site beaucoup plus complexe…
A présent le même site web, mais construit de manière responsive
Cette fois ci, ce n’est pas au visiteur de zoomer et de se déplacer pour arriver à lire, mais bel et bien le site qui s’adapte à ce petit écran pour rester lisible et garder un confort de navigation. Ainsi les éléments d’un site responsive peuvent être redimensionnés, placés autrement et même parfois supprimés pour que l’ensemble soit accessible et lisible depuis l’écran d’un téléphone mobile ou d’une tablette. Le contenu du site reste scrupuleusement le même, seule la mise en page change pour s’adapter.
Quelle est la différence avec une version mobile?
Une version mobile (ou tablette) signifie que le site web est complètement réécris et adapté pour les écrans de téléphone mobile (ou tablette) seulement. Sur un écran de bureau, un site mobile apparaîtra comme mal proportionné et inadapté.
Une version mobile a un coût, en effet, cela demande la réécriture complète du site web, soit le contenu mais aussi la mise en page (HTML/CSS) avec ce que cela peut sous-entendre comme problèmes de maintenance, mise à jour et redondance liées directement à cette réécriture. Cela signifie que chaque mise à jour du site web devra être répercutée sur la version mobile de ce même site. Cela peut vite coûter beaucoup de temps et d’argent.
Qu’est ce qu’une application mobile?
Une application mobile c’est un logiciel qui a été développé dans un langage propre au système d’exploitation du mobile ou de la tablette. L’avantage de ce développement c’est que le logiciel est parfaitement adapté et très performant sur votre appareil. De plus, l’application étant locale à votre téléphone ou tablette, elle ne nécessite pas forcément une connexion à internet pour fonctionner grâce aux stockage de bases de données sur votre téléphone.
Le revers de la médaille c’est que pour une même application, il sera nécessaire de créer autant de programme qu’il existe de systèmes. Par exemple, il faudra créer une application dans le langage objective C pour qu’elle fonctionne sur les téléphones de la gamme Apple (IOS), mais également une autre application en Java pour les smartphone fonctionnant avec le système Android, il faudrait également penser aux Windows Phone et donc créer une application en C# (C Sharp).
Vous l’aurez compris, une application mobile sera très performante et offrira plus de possibilités qu’un site web, mais demandera des compétences de programmation dans de nombreux langages (autant qu’il y a de systèmes mobiles) et, si vous devez sous-traiter ces développements, cela pourra vous coûter cher.
Qu’est ce qu’on peut en conclure?
Les sites web en HTML5/CSS3 sont à privilégier autant que possible car même si ils offrent moins de possibilités qu’une application, ils ont le mérite d’être compatibles avec tous les téléphones et tablettes moderne du marché et restent abordables. D’autre part, des technologies de stockage des données dans des bases locales à votre appareil existent et permettent à une web application de fonctionner et traiter des données en local sans forcément avoir accès à internet. Ces technologies s’appellent : Web SQL, Indexed DB ou encore Local Storage.
Mais bien entendu, le choix se fera naturellement en fonction de vos besoins, vos moyens et vos clients.
Les structures de contrôle permettent comme leur nom l’indique de contrôler des conditions durant l’exécution de votre code. Cela peut varier de la valeur d’une variable en passant par le retour d’une fonction. Les structures de contrôle permettent également de traiter les éléments d’un tableau ou des listes de valeurs déterminées (par exemple : de 0 à 31).
Sans ces structures logiques, la programmation serait un véritable enfer où le choix des portion de code à exécuter reviendrai à la décision d’un humain et où il faudrait réécrire x fois la même portion de code pour traiter les x valeurs d’un tableau.
Dans les structures de contrôle et pour les langages que nous allons étudier, la condition à tester est un booléen, soit une valeur comprise entre 0 (FAUX) et 1 (VRAI). Une condition sera toujours déclenchée par un état VRAI. Si on souhaite faire le contraire, c’est à dire déclencher lorsque la vérification est fausse, il faut faire précéder son expression par un point d’exclamation !. Enfin, les conditions doivent être entourées par des parenthèses.
Les opérateurs de contrôle
Voici une liste non exhaustive des principaux symboles utilisés pour tester des conditions.
Opérateur
Signification
==
égal
!=
différent
>
strictement supérieur
<
strictement inférieur
>=
supérieur ou égal
<=
inférieur ou égal
Voici quelques exemples de conditions et leur retour booléen:
(12==13) FAUX
(13==13) VRAI
(12==(12+1)) FAUX
(12==(13-1)) VRAI
(13 > 12) VRAI
(12 < 13) VRAI
(12 > 13) FAUX
(13 >= 13) VRAI
(12!=13) VRAI
SI ou SINON et SINON-SI
La première structure de contrôle et aussi la plus simple consiste à vérifier une condition et à exécuter des instructions en fonction qu’elle soit vrai ou fausse. Il est également possible de tester plusieurs conditions dans une structure SI avec SINON-SI.
Voici comment se présente cette structure
SI (CONDITION VRAI) ALORS// Instructions à exécuter si la condition est vraiSINON// Instructions à exécuter si la condition est fausse
Simple n’est-ce pas? Si la condition est vrai, on exécute les instructions définies en haut, sinon les autres. On peut même ne pas spécifier d’instruction pour SINON si ce n’est pas utile.
Pour illustrer l’exemple ci-dessous avec une valeur
SI (12<13) ALORS AFFICHER '12 est inférieur à 13'
Ici pas de sinon, 12 sera toujours inférieur à 13 et ce n’est pas la crise ni les attaques terroristes qui pourront y changer quelque chose…
Voici comment s’utilise cette structure en C
#define <stdio.h>#define <stdlib.h>intmain(void){int a=13;int b=12; /* SI */if(a > b){printf("La valeur de a est supérieure à la valeur de b\n");} /* SINON */else{printf("La valeur de a est inférieure à la valeur de b\n");} /* Affichera : La valeur de a est supérieure à la valeur de b */ a=12; b=13 : /* SI */if(a > b){printf("La valeur de a est supérieure à la valeur de b\n");} /* SINON */else{printf("La valeur de a est inférieure à la valeur de b\n");} /* Affichera : La valeur de a est inférieure à la valeur de b */}
en Perl à présent
# !/usr/bin/perluse strict ;my$a=13 ;my$b=12 ;# SIif ($a > $b) {# Instructionsprint"La valeur de a est supérieure à la valeur de b\n" ;}# SINONelse {# Instructionsprint"La valeur de a est inférieure à la valeur de b\n" ;}# Affichera : La valeur de a est supérieure à la valeur de b$a=12 ; $b=13 ;# SIif ($a > $b) {# Instructionsprint"La valeur de a est supérieure à la valeur de b\n" ;}# SINONelse {# Instructionsprint"La valeur de a est inférieure à la valeur de b\n" ;}# Affichera : La valeur de a est inférieure à la valeur de b
Au tour de PHP
<?php$a=13;$b=12;// SIif($a>$b){// Instructionsecho"La valeur de a est supérieure à la valeur de b<br/>";}// SINONelse{// Instructionsecho"La valeur de a est inférieure à la valeur de b<br/>";}// Affichera : La valeur de a est supérieure à la valeur de b$a=12;$b=13;// SIif($a>$b){// Instructionsecho"La valeur de a est supérieure à la valeur de b<br/>";}// SINONelse{// Instructionsecho"La valeur de a est inférieure à la valeur de b<br/>";}// Affichera : La valeur de a est inférieure à la valeur de b?>
Et finalement en Javascript
vara=13;varb=12;// SIif (a>b) {// Instructionsconsole.log('La valeur de a est supérieure à la valeur de b') ;}// SINONelse{// Instructionsconsole.log('La valeur de a est supérieure à la valeur de b') ;}// Affichera : La valeur de a est supérieure à la valeur de ba=12;b=13;// SIif (a>b) {// Instructionsconsole.log('La valeur de a est supérieure à la valeur de b') ;}// SINONelse{// Instructionsconsole.log('La valeur de a est supérieure à la valeur de b') ;}// Affichera : La valeur de a est inférieure à la valeur de b
La structure de contrôle SI-SINON existe dans la majorité des langages de programmation et est indispensable pour prendre des décisions dans un programme. On ne peut s’en passer et vous verrez par la suite que ceraines structures de contrôles plus complexes reposent sur celle-ci.
TANT QUE
Cette structure de contrôle fait partie des boucles. Parce que, tant que la condition est vrai, nous allons exécuter les mêmes instructions. Attention toutefois à réaliser les bons contrôles pour sortir de la boucle sans quoi votre programme peut boucler à l’infini (jusqu’à interruption manuelle).
Elle se présente comme suit
TANT-QUE (CONDITIONVRAI) {// Instructions à exécuter à chaque passage dans la boucle}
Voici ce que ça donne en C
#define <stdio.h>#define <stdlib.h>intmain(void){int position=12;int max=24; /* Tant que position est inférieur à max */while(position < max){ /* Instructions à exécuter tant que position est inférieur à max */printf("Valeur de position : %d\n", position); /* Affiche la valeur de position */ position++ /* On augmente position de 1 à chaque passage */} /* La boucle affichera les valeurs de 12 à 23 puisque 24 étant == à max on sort de la boucle avant de l'afficher */}
En perl
# !/usr/bin/perluse strict ;my$pos=12 ;my$max=24 ;# Tant que pos est inférieur à maxwhile ($pos <= $max) {# Affiche la valeur de pos à chaque passageprint"Valeur de pos : $pos\n" ;# Incrémente la valeur de pos à chaque passage (ajoute 1)$pos++ ;}# La boucle affichera les valeurs de 12 à 24 puisque nous avons utilisé l'opérateur <= (inférieur ou égal)
En PHP
<?php$pos=12;$max=24;// Tant que pos est inférieur à maxwhile($pos<$max){// Affiche la valeur de pos à chaque passageecho"Valeur de pos : $pos<br/>";// Incrémente la valeur de pos à chaque passage (ajoute 1)$pos++;}/* La boucle affichera les valeurs de 12 à 23 puisque 24 étant == à max on sort de la boucle avant de l'afficher */?>
En Javascript
varpos=12;varmax=24;while (pos<=max) {// Affiche la valeur de pos à chaque passage (dans la console)console.log('Valeur de pos : '+pos) ;// Incrémente la valeur de pos à chaque passage (ajoute 1)$pos++;}/* La boucle affichera les valeurs de 12 à 24 puisque nous avons utilisé l'opérateur <= (inférieur ou égal) */
Dans les articles à venir nous allons étudier d’autres structures de contrôle plus complexes ou plus spécifiques à certains langages. Ces structures sont là pour faciliter le travail du développeur, aider à prendre des décision dans un programme mais aussi à parcourir des tableaux de donnée ou encore à traiter des ensembles de cas de figures spécifiques.
Cet article a pour vocation de décrire brièvement et simplement les différents types de téléphonies utilisées aujourd’hui. il ne se revendique en aucun cas d’être complet.
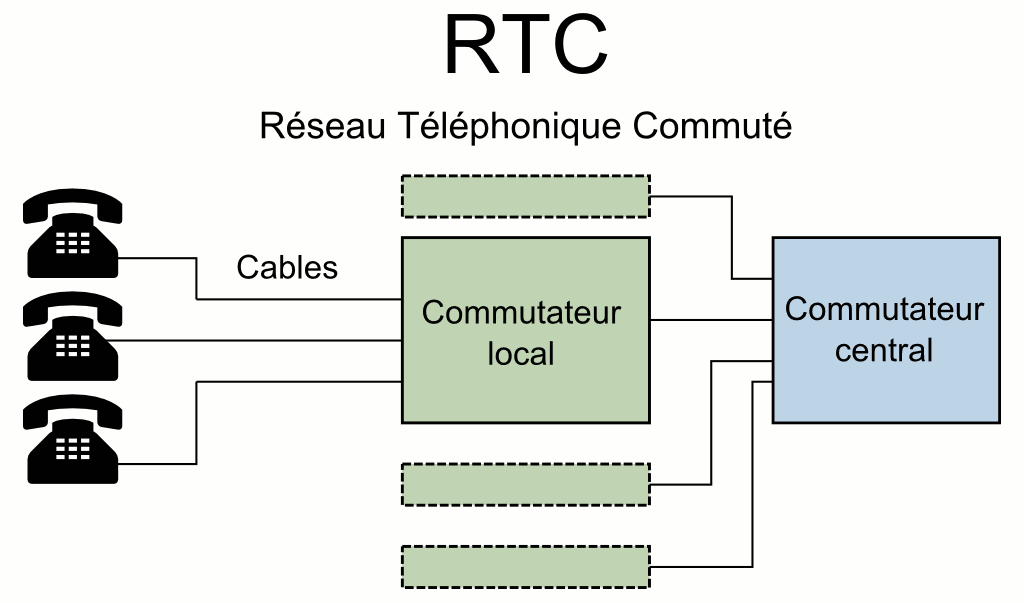
Le Réseau Téléphonique Commuté (RTC)
C’est le plus vieux système de téléphonie utilisé en France. Toujours existant, et bien qu’ayant évolué depuis sa création, ce dernier fonctionne de manière assez simple. Un mécanisme associé à des composants électroniques simples envoient des impulsions électriques à un commutateur, lui indiquant le numéro de votre destinataire. Les commutateurs reliés entre eux, déterminent et ferment les circuits nécessaires pour vous mettre en lien avec votre correspondant. Pour le reste, un simple système de micro et d’écouteur se chargent d’enregistrer et restituer la voix au travers d’une paire de fils de cuivre. Des filtres électroniques et un système de modulation de fréquence permettent de faire passer plusieurs conversations en simultané sur une même ligne physique. Au départ, un lien électrique existait entre les deux correspondants. Les systèmes ayant été informatisés depuis, ce n’est plus le cas désormais.
Pour téléphoner via le Réseau Téléphonique Commuté, il faut généralement utiliser un téléphone fixe (à cadran ou à touches) équipé d’une prise gigogne mais aussi avoir un abonnement chez l’opérateur français historique, Orange (anciennement France Télécom).
Chez Orange, un abonnement au réseau RTC coûte 16.96 €. En France métropolitaine, le raccordement d’une nouvelle ligne téléphonique coûte 55 € + 69 € si le déplacement d’un technicien est nécessaire. (source: Boutique Orange)
Le réseau téléphonique sans fil (GSM)
GSM: Global System for Mobile Communications soit Système Global pour Communications Mobiles
Le développement du réseau GSM à commencé en France durant la seconde moitié des années 80. Les premiers téléphones GSM français datent du début des années 90 mais restent des objets rares et exceptionnels. C’est seulement à la fin des années 90, début des années 2000 que le marché de la téléphonie mobile explose réellement, atteignant en quelques années l’ampleur qu’on lui connaît aujourd’hui.
Pour accéder au réseau GSM, vous devez posséder un téléphone mobile et acheter une carte SIM chez opérateur de téléphonie mobile comme par exemple: Orange, SFR, Bouygues. Son fonctionnement est plus complexe que celui de la téléphonie RTC. Ici le téléphone mobile est une véritable prouesse de composants électroniques avancés, alliant performances et faible consommation. Votre voix est échantillonnée afin d’être numérisée puis compressée avant d’être envoyée sous la forme de signaux radio haute fréquence à l’antenne relais la plus proche qui se chargera au choix de renvoyer ce signal vers une autre antenne relais dans le cas d’une communication de mobile à mobile, soit de relayer via un commutateur les données décodées dans le cas d’une communication mobile vers fixe.
En moyenne les tarifs d’un abonnement mensuel vont de 2 € à 70 € pour le particulier. Pour plus de détails, vous pouvez utiliser des comparateurs de forfait mobile comme il en existe plein sur la toile.
Téléphoner via INTERNET (VoIP et SIP)
VoIP: Voice on IP ou voix sur IP. Correspond au principe de véhiculer du son (votre voix, celle de votre correspondant) au travers du réseau informatique utilisé sur internet soit TCP/IP.
SIP: Session Initiation Protocol ou Protocole d’Initiation de Session. Protocole ouvert, normalisé et standardisé utilisé dans les communication téléphoniques ou visiophoniques.
Ce système de communication s’est développé avec l’avènement de l’internet à la fin des année 90, début des années 2000. Comme pour la téléphonie mobile, votre voix est échantillonnée et numérisée au travers d’un micro et de la carte son de votre ordinateur puis compressée et encodée par un logiciel qui va s’occuper de l’envoyer au logiciel de votre correspondant pour qu’elle y soit décodée puis entendu. Et ceci en temps réel ou presque. Pour les plus connus de ces logiciels, nous pouvons citer Net Meeting de Microsoft, mais aussi Skype et plus récemment Mumble ou encore TeamSpeak.
Pour le prix de votre forfait internet, vous pouvez téléphoner en Australie ou aux Etats-Unis sans vous poser de question sur la durée de vos conversations (sauf si votre accès n’est pas illimité). Toutefois, les communications sur internet ne pouvaient en aucun cas interagir avec les réseaux de téléphonie existant et inversement. C’est alors que sont arrivés les opérateurs SIP qui, dans le courant des années 2000 ont permit le lien entre la VoIP sur Internet et la téléphonie. L’opérateur SIP est en quelque sorte le fil qui relie la téléphonie classique (qu’elle soit analogique via RTC ou numérique) et la VoIP utilisée sur Internet. Ces opérateurs possèdent des numéros de téléphone dans le monde entier et vont vous permettre de les utiliser depuis votre logiciel de téléphonie SIP sur Internet.
Vous vivez en France et vous déciez de louer un numéro de téléphone Australien. Vous pouvez être appelé par tous les Australiens comme si vous étiez un habitant local et sans supplément de forfait. Inversement, vous pouvez téléphoner de partout en Australie au tarif d’un appel local alors que vous habitez en France. Pour résumer, votre opérateur sera le lien entre la communication VoIP sur internet et les réseaux de téléphonies GSM ou RTC.
Dans l’hypothèse inverse, vous êtes en vacances aux USA. Votre numéro SIP français, vous permet d’être appelé par n’importe qui en France au prix d’un appel local et vous pouvez également appeler n’importe qui en France depuis un numéro local sans payer de supplément. De plus, certains opérateurs vous proposent de relayer les messages laissés sur le répondeur de votre téléphone SIP en pièce jointe par e-mail.
Pour accéder à des services de téléphonie SIP, vous devez créer un compte (gratuit pour certains) chez un opérateur SIP comme: IPPI ou encore OVH. D’autres sociétés comme Microsoft et Google proposent des services similaires au travers de leur application respective Skype et Google Talk. Il faut également être équipé au choix, d’un logiciel permettant de se connecter à un opérateur de téléphonie SIP aussi appelé softphone (téléphone logiciel) comme: Ekiga, Zoiper ou encore X-Lite. Vous pouvez également acheter un téléphone physique VoIP ou utiliser votre smartphone comme un softphone une fois celui-ci connecté à internet. Vous pouvez même utiliser votre téléphone fixe ou mobile et appeler en utilisant votre numéro SIP grâce aux options proposées par certains opérateurs!
En moyenne les premiers prix d’un abonnement SIP en France débutent à 1.20 €. Après cela va dépendre du nombre de numéros que vous possédez, dans quels pays vous possédez ces numéros et la quantité d’appels que vous allez passer avec. Bien entendu, ces appels sont totalement gratuits lorsqu’ils restent entre opérateurs SIP et qu’ils transitent par internet. Cela change dès qu’on arrive sur des réseaux physiques. Vous pouvez vous équiper d’un groupe de 10 lignes téléphoniques en VoIP à moindre coût et sans avoir à vous encombrer avec du matériel cher et encombrant comme c’est le cas avec la téléphonie classique d’entreprise.
Certaines offres grand public (triple play avec box) utilisent le système de la téléphonie VoIP. (Free, Numericable…)
En bref…
RTC: Solution de communication analogique basée sur un réseau filaire. Relativement chère et limitée à la position géographique de votre ligne.
GSM: Solution de communication numérique basée sur un réseau sans fil. Peu cher et permet de se déplacer de partout. Prévoir des surcoûts pour les communications depuis l’étranger.
VoIP: Solution de communication numérique basée sur un réseau informatique et à travers internet. Peut être gratuit entre deux postes sur internet, le coût reste faible même sur des appels hors internet. Permet d’être joignable et de téléphoner depuis n’importe où pourvu d’avoir accès à internet. Vous pouvez téléphoner sans avoir besoin de posséder un téléphone physique et sans contrainte géographique.
Cet article, sera le dernier de la série sur les variables traitera d’un type de variable très utile que sont les variables tableaux ou array en anglais.
Voici comment une variable tableau pourraît être représentée:
Numéro ou Index
Valeur
0
Albert
1
André
2
Bertrand
3
Corinne
4
Félicie
x
…
Une variable tableau est une liste de données rangées sous la forme d’un tableau indicé. Par exemple l’indice 0 contient Albert, l’indice 3 contient Corinne.
Voici la définition d’un tableau destiné à contenir 5 entiers en C:
// Définition de 5 emplacements pour entiersint monTableau[5];// Initialisation des emplacements (== indices)// Premier emplacementmonTableau[0]=101;// Second emplacementmonTableau[1]=102;// Troisième emplacementmonTableau[2]=103;// nième emplacementmonTableau[n-1]=nnn;
Si l’indice x de la variable monTableau est modifié à x + 1, alors le curseur en mémoire avancera de la taille d’un int. A l’inverse, si l’indice est modifié à x – 3, alors le curseur reculera de 3 fois la taille d’un int. Survolez les int présents dans le tableau ci-dessous.
Position en mémoire
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Taille d’un élément
int 1
int 2
int 3
int 4
int 5
Chaque int pesant (hypothèse sur un système 32 bits) 4 octets, lorsqu’on avance d’un int, on déplace le curseur de 4 octets en mémoire.
En C le type chaîne de caractères n’existe pas comme on peut le trouver dans les autres langages. Il s’agit en fait d’un tableau de caractères qui peut se définir comme suit:
// On réserve 20 caractèreschar maChaine[20];// On réserve 11 caractères et on initialise le contenu de la variable// Oui 11 et pas 10 car en C une chaîne doit se terminer par le caractère \0// Il faut donc toujours prévoir un caractère de plus par rapport à la taille de la chaîne à contenirchar maChaine[]="Bonjour!!!";// Equivalent de:char maChaine[32];maChaine[0]='B';maChaine[1]='o';maChaine[2]='n';maChaine[3]='j';maChaine[4]='o';maChaine[5]='u';maChaine[6]='r';maChaine[7]='!';maChaine[8]='!';maChaine[9]='!';maChaine[10]='\0';/* ... etc ... */// Equivalent de:char maChaine[]={'B','o','n','j','o','u','r','!','!','!','\0'};printf("%c - %c - %c", maChaine[0], maChaine[1], maChaine[2]); // Affichera B - o - n
Tous les types de variables peuvent être ordonnés en tableau. On retrouve les tableaux dans la majorité des langages de programmation modernes. Il est possible également de créer des tableaux contenant des tableaux. Attention toutefois à ne pas sombrer dans la complexité et ne perdez jamais de vue que tout cela a un coût en mémoire.
Définition de deux tableaux en PHP:
<?php// Tableau indicé$epices=array('poivre','cumin','piment','coriandre','curry');// Equivalent de$epices=array();$epices[0]='poivre';$epices[1]='cumin';$epices[2]='piment';$epices[3]='coriandre';$epices[4]='curry';echo"Un peu de ".$epices[2]."?";// Affichera: Un peu de piment?// Tableau associatif// On remplace l'index numérique par une chaîne de caractères appelée clé// Ainsi le tableau associatif, comme son nom l'indique devient un tableau d'associations de clé=>valeur$fiche=array('nom'=>'Dupont','prenom'=>'Henry','email'=>'hdupont@exemple.org');// Pour accéder à l'adresse email de monsieur dupont, il suffit d'appeler la variable ainsiecho$fiche['email'];// Affichera: hdupont@exemple.org
Définition de deux tableaux en Javascript:
// Tableau indicéepices=['poivre','cumin','piment','coriandre','curry'];// Equivalent de:epices=[];epices[0]='poivre';epices[1]='cumin';epices[2]='piment';epices[3]='coriandre';epices[4]='curry';console.log('Aimez-vous le '+epices[1] +'?');// Affichera dans la console Javascript: Aimez-vous le cumin?// Tableau associatif// Même fonctionnement qu'en PHP, seule la syntaxe changefiche={'nom':'Dupont','prenom':'Henry','email':'hdupont@exemple.org'};// Deux méthodes permettent d'accéder à l'adresse email de monsieur dupontconsole.log(fiche['email']);// Affiche hdupont@exemple.org dans la console javascript// Ouconsole.log(fiche.email);// Affiche hdupont@exemple.org dans la console javascript
Définition de deux tableaux en Perl:
# Déclaration d'une variable tableau (indicé)my@epices;# Initialisation du contenu du tableau@epices=('poivre', 'cumin', 'piment', 'coriandre', 'curry');print"Encore un peu de ".$epice[0]."?"; # Affichera: Encore un peu de poivre?# Equivalent de:@epices=();$epices[0]='poivre';$epices[1]='cumin';$epices[2]='piment';$epices[3]='coriandre';$epices[4]='curry';print"Encore un peu de ".$epice[0]."?"; # Affichera: Encore un peu de poivre?# En perl, on définit une variable tableau en faisant précéder son nom d'un @# Mais pour accéder à ses valeurs, on utilise le symbole $ comme une variable classique# Tableau associatif (aussi appelé table de hachage)my%fiche=('nom'=>'Dupont', 'prenom'=>'Henry', 'email'=>'hdupont@exemple.org');print$assoc{'email'}."\n"; # Affichera: hdupont@exemple.org
L’utilité de ce type de variable c’est de pouvoir traiter un grand volume de données avec un seul algorithme.
Par exemple, prenons l’algorithme suivant (en PHP):
<?php// Liste d'abonnés$liste=array('jacques'=>'jacques@truc.info','Henry'=>'henry@machin.fr','Mike'=>'mike@chose.com','Pierre'=>'pierre@bidule.net');// On envoie le même mail à tous les abonnés// A chaque passage dans cette boucle $clé contient le nom de l'abonné et $valeur l'adresse email de l'abonné// Initialisation du sujet du mail$sujet='Joyeuses fêtes';foreach($listeAS$cle=>$valeur){// Initialisation du contenu du mail$message="Bonjour ".$cle."!".PHP_EOL.PHP_EOL."Le blog ANDEE vous souhaite de joyeuses fêtes de fin d'année!".PHP_EOL;// Cette fonction n'existe pas, c'est une hypothèse pour l'exempleenvoyerUnMail($sujet,$message,$valeur);}
Dans l’exemple ci-dessous, nous avons envoyé un mail personnalisé à tous les abonnés avec un seul code. Grâce à l’utilisation d’un tableau associatif nous avons réussi à écrire un code simple qui traite une liste d’abonnés et envoie un mail à chacun d’eux.
Les tableaux sont la solution pour traiter des informations en masse avec un code simple et réexploitable.
Maintenant que nous avons parcouru la plupart des types de variables, nous pourrons étudier à partir du prochain article les structures de contrôle et commencer à faire des choses concrètes.
Vous n’êtes pas inspiré? Vous hésitez sur le choix de votre nom de domaine? Vous avez du mal à mesurer l’impact que cela aura sur l’adresse de votre site web, votre blog ou encore votre messagerie professionnelle?
Voici quelques astuces à connaître ainsi qu’un petit outil interactif conçu pour vous orienter. Ce dernier va générer pour vous et en fonction des paramètres que vous aurez saisi, des suggestions de nom de domaine et, pour chacun, plusieurs exemples d’adresse e-mail et d’URL de site web pour vous donner un avant goût et vous aider à mieux choisir.
Les adresses les plus courtes sont plus simples à retenir.
Ex: h.dupont@dupont.com sera plus facile à retenir que henry.dupont@lasupersocietedehenrydupont.com
Les adresses qui ont un sens restent plus facilement en mémoire.
Ex: http://outillage.fr/support sera plus facile à retenir que http://www.odsarl.fr/Main/pages?module=support
Un nom de domaine contenant un ou plusieurs mots clés représentatifs de votre activité sera un atout pour votre référencement sur internet.
Ex: http://materiel-electrique.fr vous donnera plus de résultats pour une recherche avec les mots clé « matériel électrique » que http://www.od-system.fr
Si vous avez plusieurs services et des employés, utilisez de préférence un nom générique et explicite pour vos adresses mail plutôt qu’un nom prénom qui peuvent changer et ne représentent pas le service.
Ex: contact@materiel-electrique.fr sera plus simple à gérer que jerome.de-latelier@materiel-electrique.fr surtout si vous avez du personnel intérimaire ou en CDD.
Voici un article pour les curieux comme moi qui se demandent combien de pages (about:blank, about:plugins) sont cachées à l’interieur du célèbre navigateur Mozilla Firefox et ce qu’elles renferment.
Cette liste n’a pas pour vocation d’être exhaustive, si vous avez plus d’informations sur ces pages ou que vous connaissez des pages non listées ci-dessous, je vous invite à m’en faire part via les réseaux sociaux, par mail ou via les commentaires de ce blog.
La version de Firefox en cours à la date de rédaction de cet article est 34.0.5.
about:
Contient un bref résumé du navigateur avec des détails comme la version en cours l’identifiant de compilation (USER_AGENT) mais aussi d’autres liens internes vers des pages cachées:
Le logo officiel du navigateur dont le lien pointe vers about:logo
Liste des contributeurs about:credits
Des informations sur la licence d’utilisation about:license
La configuration de compilation pour cette version about:buildconfig
about:accounts
Cette page vous propose de synchroniser votre navigateur (mot de passe, onglets, historique et bien d’autres) avec votre compte Firefox Sync.
about:addons
Ce lien pointe vers la section des extensions, addons, thème et plugins de Firefox.
about:app-manager
Vous donne accès au gestionnaire d’applications qui permet d’installer ou de créer des applications web sur des appareils compatibles notamment à base de Firefox OS.
about:blank
Affiche une page vierge. Cette page correspond au choix Afficher une page vide dans les options de démarrage de Firefox.
about:blocked
Cette page contient le message de mise en garde que Firefox affiche lorsque vous tentez d’accéder à une page déclarée comme contrefaite ou malveillante.
about:buildconfig
Contient des paramètres et détails de compilation du navigateur que vous utilisez. Généralement réservé aux développeur et aux geeks.
about:cache
Donne des informations intéressantes sur le cache (espace utilisé en mémoire et sur le disque) de Firefox. Les indications données sont la taille ainsi que son emplacement sur votre disque. Vous pouvez également utiliser les filtres présents dans la page pour avoir plus de détails concernant la répartition du cache en fonction des sites, pages web, scripts, image et autres médias.
about:certerror
Contient le message de mise en garde que Firefox affiche lorsque vous tentez d’accéder à une page via le protocole sécurisé https mais lorsque le certificat utilisé n’est pas reconnu ni certifié.
about:compartments
Déplacé vers about:memory
about:config
Cette page vous propose de modifier des paramètres spécifiques et cachés de Firefox allant de l’emplacement de certains fichiers en passage par l’activation ou non des mises à jours automatiques, mais également le style par défaut des balises HTML. Avant de vous donner un libre accès à cette page de paramètre, Firefox vous met toutefois en garde contre les dégats potentiels que peuvent entrainer certaines modifications et vous faît promettre (en cliquant sur un bouton) d’être très prudent.
about:crashes
Affiche une liste des rapports de plantage envoyés.
about:credits
La liste des personnes ayant contribué au développement de Firefox classé par ordre alphabétique.
about:customizing
Affiche la page de personnalisation de Firefox (outils, fonctionnalités, thèmes).
about:downloads
Affiche la liste de vos téléchargements. Vous pouvez obtenir cette même page via le menu outils/Téléchargements ou en utilisant la combinaison de touches Ctrl+J.
about:feeds
Affiche la page proposée par Firefox lorsque vous souhaitez vous abonner à un flux RSS.
about:healthreport
Affiche un bilan de santé détaillé de Firefox. Vous trouverez des informations intéressantes concernant votre navigateur comme un récapitulatif d’activité (nombre de minutes d’utilisation), un graphique avec les temps de démarrage de Firefox mais aussi la possibilité de partager ou non ces informations avec Mozilla.
about:home
Affiche la page par défaut de Firefox utilisée à la première installation et à défaut d’un autre paramétrage. Permet de faire une recherche Google avant l’ouverture de tout autre page sur internet.
about:license
Affiche la licence du navigateur Mozilla Public License 2.0 (MPL) ainsi qu’une liste de liens vers les licences d’éléments associés de Firefox (protocoles, plugins, média, librairies …).
about:logo
Affiche le logo de Firefox.
about:memory
Cette page permet d’afficher la mémoire utilisée par Firefox, sa répartition détaillée par processus. En prime, il vous est proposé d’enregistrer ces mesures puis de les recharger ultérieurement afin de réaliser des comparatifs. D’autres boutons vous permettent d’activer le garbage collector et de minimiser l’utilisation de la mémoire par Firefox. Très utile pour récupérer quelques dizaines de Mo après une avoir fermé une série d’onglets.
about:mozilla
Affiche un extrait de l’inquiétant livre de Mozilla. Cette extrait est réputé changer à chaque nouvelle version du navigateur.
Le livre de mozilla
http://fr.wikipedia.org/wiki/Le_Livre_de_Mozilla
https://www.mozilla.org/en-US/book/
about:neterror
Contient la page d’erreur que Firefox affiche lorsqu’une erreur réseau empêche l’accès à une page web.
about:newtab
Affiche au choix (paramètres) une page blanche ou un damier avec des liens vers les pages que vous avez visité comme lorsque vous venez d’ouvrir un nouvel onglet.
about:permissions
Cette page est très pratique puisqu’elle permet de paramétrer les permissions que vous donnez à chaque site que vous visitez, comme par exemple l’accès à votre géolocalisation, votre webcam, mais aussi l’utilisation de cookies, le blocage des popup et bien d’autres détails.
about:plugins
Affiche un listing très détaillé des plugins installés sur votre navigateur ainsi que les types MIME qu’ils traitent respectivement.
about:preferences
Vous donne accès au paramétrage de votre Firefox via une série de pages web similaire aux options que vous pouvez retrouver dans le menu Outils/Options. Cette présentation rappelle fortement le système de configuration de Google Chrome.
about:privatebrowsing
Vous propose l’ouverture d’une fenêtre de navigation privée. La navigation privée, vous permet de naviguer de manière anonyme sans enregistrement de l’historique ou des cookies.
about:rights
Vous propose un petit rappel sur vos droits en tant qu’utilisateur de Firefox.
about:robots
Affiche une page humoristique (easter eggs en anglais) contenant un message que les robots souhaitent vous communiquer. Notez que le titre de la page « Gort! Klaatu barada nikto! » fait référence à une réplique tirée du film de science fiction Le Jour où la Terre s’arrêta de Robert Wise (1951). Cette même réplique a depuis été réutilisée maintes fois dans de nombreux autres films.
about:sessionrestore
Affiche la page de restauration de session. Cette page s’affiche habituellement lorsque que vous relancez Firefox après un plantage. Ce dernière vous propose de recharger l’ensemble des pages dans l’état exact où elle étaient au moment du crash.
about:support
Cette page est remplie d’informations techniques propres à votre navigateur. Vous y retrouverez entre autres:
Le nom du navigateur (des fois que…)
La version en cours
L’historique des mises à jour
L’accès aux fichiers de votre dossier de profil (contenant entre autre vos cookies, historique et favoris)
Une liste d’extension installées
Une liste de paramètres critiques
Un bouton vous proposera de copier ce contenu dans le presse papier pour pouvoir le coller dans un mail ou un document par exemple. Un autre vous permettra de restaurer Firefox dans son état initial (attention soyez prudents!).
about:sync-tabs
Affiche les onglets d’autres appareils connectés avec Firefox via Sync.
about:sync-progress
Page que Firefox affiche lorsque vous avez terminé de paramétrer Sync.
about:telemetry
Vous donne accès à une page technique permettant d’activer la récolte de données télémétriques de Firefox. Après plusieurs utilisations de Firefox avec la télémétrie activée, vous aurez accès à des graphiques et histogrammes de performance des différents composants du navigateurs (internes ou plugins ajoutés).
about:webrtc
Cette page permet d’activer le mode debug (mode bavard) de webRTC. webRTC est une solution de communication audio et vidéo comme Skype ou Google Talk à la différence qu’elle est réputée ne demander aucun compte ni aucune inscription sur quelque plateforme que ce soit. Cette fonctionnalité est encore en cours de développement. Pour en savoir plus, suivez ce lien: Blog de la fondation Mozilla.
about:welcomeback
Ceci est la page que Firefox affiche après un plantage du navigateur et que ce dernier a réussi à réinitialiser votre profil. Il vous propose au choix de restaurer les fenêtres et onglets ouverts ou de démarrer une nouvelle session.
about:about
Aussi intitulée À propos de « À propos » cette page récapitule bon nombre des liens que nous avons parcouru ensemble tout au long de cet article..
Dans l’article précédent, nous avons défini ce qu’était une variable, une constante. Nous avons également introduit la notion de typage même présenté différents types de variables. Toutefois il existe encore d’autres types très importants en programmation et nous allons tâcher de les présenter dans cet article. Rappel sur les variables
Une variable c’est quoi?
Nous avons vu plus tôt qu’une variable représentait l’association entre un mot et une valeur. Nous avons vu également qu’une variable était définie par son type, qui va déterminer sa taille en octets et la manière de stocker et traiter les données contenues afin d’en interprêter la valeur.
Pour faire plus simple, une variable c’est donc un espace mémoire dédié au stockage d’une valeur auquel on associe un mot (ex: maVariable).
En C une variable se défini ainsi
/* On défini une variable nommée maVariable et on l'initialise avec la valeur 5 */int maVariable=5;
En PHP une variable se défini ainsi
<?php/* On défini une variable nommée $maVariable et on l'initialise avec la valeur 5 */$maVariable=5;
En Javascript une variable se défini ainsi
/* On défini une variable nommée maVar et on l'initialise avec la valeur 5 */varmaVariable=5;
En Perl une variable se défini ainsi
# On définit une variable nommée maVariable et on l'initialise avec la valeur 5my$maVariable=5;
Notez qu’il est important de toujours initialiser (attribuer une valeur) ses variables. Si vous ne le faîtes pas, vous pouvez vous retrouver avec des variables contenant des valeurs inconnues et non maîtrisées qui peuvent planter votre programme.
Un pointeur c’est quoi?
Un pointeur, c’est une variable qui va contenir en guise de valeur, l’adresse d’une autre variable. Par exemple:
En C un pointeur se défini comme suit:/* On défini un pointeur nommé monPointeur et on le fait pointer vers l'adresse (adresse mémoire) d'une variable. */int*monPointeur=&maVariable;
Le symbole & indique au compileur que nous ne voulons pas la valeur de la variable (soit 5) mais l’adresse mémoire à laquelle il a rangé cette valeur. Ainsi l’affichage de &maVariable pourrait donner 0x12aec345. (Correspond à une adresse mémoire en 32 bits)
Le symbole * précise que nous ne demandons pas la création d’une variable de type int, mais bien d’un pointeur dont l’adresse de destination va contenir une valeur de type int.
Quel est l’intérêt des pointeurs?
En C les pointeurs sont très utilisés pour donner aux fonctions (que nous étudierons plus tard) l’accès à de grosses quantités de données rapidement. il faut savoir que lorsqu’on appelle une fonction avec en paramètres des variables, nous ne donnons qu’une copie des valeurs contenues dans ces variables à la fonction. Elle ne peut que les utiliser pour faire des calculs ou d’autres copies, mais en aucun cas les modifier. C’est là qu’interviennent les pointeurs.
/* Illustration en C *//* Dans ma variable Big, je stocke 1Go de données dans un type imaginaire */monGrosType Big="1 Go de données";/* Si je dois la donner en paramètre d'une fonction */maFonction(Big);/* le système va d'abord réaliser une copie locale de Big et donc consommer 1Go de mémoire en plus alors que ce n'est pas utile et en prime, il va consommer du temps processeur le temps de copier les 1Go de données. */
En résumé, nous perdons beaucoup de temps et beaucoup de mémoire pour une opération aussi anodine que l’exécution d’une fonction. Soit quelque chose qui ne devrait pas prendre plus de quelques millisecondes sur un système moderne. Imaginez un peu sur les jeux vidéos moderne la perte de temps que cela représenterai si le système copiait 1Go de donnée à chaque fois qu’un objet se déplace à l’écran en perdant plusieurs secondes. On serait loin des performances connues aujourd’hui.
/* Le même exemple avec un pointeur *//* P_Big contient la position en mémoire du contenu de la variable Big */monGrosType *P_Big=&Big;/* Ici ma fonction est prévue pour travailller avec un pointeur */maFonction(P_Big);/* Elle récupère donc l'adresse contenu dans P_Big soit 4 octets en 32 bits et 8 octets en 64 bits. */
Vous admettrez qu’entre 8 octets max et 1Go la différence est toute faîte. Nous gagnons ici un temps processeur précieux et une quantité de mémoire non négligeable.
Les pointeurs sont spécifiques aux langages C et C++. Dans d’autres langages, on parle de référence, mais attention! Même si on retrouve quelques similarité, il ne s’agit pas de la même chose. Bien d’autres usages spécifiques sont réservés aux pointeurs, nous n’avons vu ici que la base.
Une référence c’est quoi?
Une référence est un type de variable qui partage quelques similarités avec les pointeurs, mais qui ne sont pas des pointeurs.
En PHP
<?php/* Initialise le contenu de $maVariable avec "Beaucoup de blabla" */$maVariable="Beaucoup de blabla";echo$maVariable;// Affichera: Beaucoup de blabla/* Initialise le contenu de $bobVariable avec une copie du contenu de $maVariable */$bobVariable=$maVariable;echo$bobVariable;// Affichera: Beaucoup de blabla/* Modifie le contenu de $bobVariable */$bobVariable="Coucou c'est Bob!";echo$bobVariable;// Affichera: Coucou c'est Bob!echo$maVariable;// Affichera encore: Beaucoup de blabla/* Initialise le contenu de $totoVariable avec une référence vers $maVariable */$totoVariable=&$maVariable;echo$totoVariable;// Affichera: Beaucoup de blabla/* Modifie le contenu référencé par $totoVariable */$totoVariable="Coucou c'est Toto!";echo$totoVariable;// Affichera: Coucou c'est Toto!echo$maVariable;// Affichera cette fois: Coucou c'est Toto!?>
Nous constatons
Que lorsqu’on modifie le contenu copié depuis une autre variable, cela n’affecte que le contenu de la copie, l’original reste intact.
Que lorsqu’on modifie le contenu référencé depuis autre variable, cela affecte le contenu de l’original car il n’y a pas création d’une copie. La zone mémoire pointée par $totoVariable est donc la même que $maVariable.
Qu’en PHP une référence vers une variable se fait en faisant précéder la variable d’un et commercial ‘&’
En Javascript
// Initialise le contenu de maVar avec Beaucoup de blablavarmaVar='Beaucoup de blabla';console.log(maVar);// Affiche: Beaucoup de blabla// Initialise le contenu de $bobVar avec une copie de la valeur de maVarvarbobVar=maVar;console.log(bobVar);// Affiche: Beaucoup de blabla// Modifie le contenu de la variable bobVar avec Salut c'est BobbobVar='Salut, c\'est Bob!';console.log(bobVar);// Affiche: Salut, c'est bob!console.log(maVar);// Affiche: Beaucoup de blabla/* Sur un objet à présent les choses diffèrent */// Initialisation d'un objet videvarmonObj={};// Initialisation de la propriété contenu avec Beaucoup de blablamonObj.contenu='Beaucoup de blabla';console.log(monObj.contenu);// Affiche: Beaucoup de blabla// Initialisation de l'objet bobObj avec une copie de monObjvarbobObj=monObj;console.log(bobObj.contenu);// Affiche: Beaucoup de blabla// Modification du contenu référencé dans la copie de l'objetbobObj.contenu='Salut c\'est bob!';console.log(bobObj.contenu);// Affiche: Salut, c'est bob!console.log(monObj.contenu);// Affiche: Salut, c'est bob!
Nous constatons
Que le contenu d’une variable simple est copié mais que les éléments contenus dans les objets sont des références. La zone mémoire pointée par monObj.contenu et bobObj.contenu est donc la même.
En Perl
# Initialise le contenu de $maVar avec Beaucoup de blablamy$maVar = 'Beaucoup de blabla';# Initialise le contenu de la variable $bobVar avec le contenu de la variable $maVarmy$bobVar = $maVar;print$bobVar."\n"; # Affiche: Beaucoup de blabla# Modification du contenu de la variable $bobVar$bobVar = "Salut c'est Bob!";print$bobVar."\n"; # Affiche: Salut c'est Bobprint$maVar."\n"; # Affiche: Beaucoup de blabla# Initialise le contenu de la variable $totoVar avec une référence vers le contenu de $maVarmy$totoVar = \$maVar;print$$totoVar."\n"; # Affiche: Beaucoup de blabla# Modifie le contenu référencé par $totoVar$$totoVar = "Salut c'est Toto!";print$$totoVar."\n"; #Affiche: Salut c'est Toto!print$maVar."\n"; #Affiche: Salut c'est Toto!
Nous constatons
Que lorsqu’on modifie le contenu copié depuis une autre variable, cela n’affect que le contenu de la copie, l’original reste intact.
Que lorsqu’on modifie le contenu référencé depuis une autre variable, cela affecte le contenu de l’original car il n’y a pas création d’une copie.
La zone mémoire piontée par $totoVar est donc la même que $maVar.
Qu’en Perl les références sont appelée en faisant précéder le nom de la variable par un antislash ‘\’
Qu’en Perl le contenu pointé par une référence s’appelle en faisant précéder le nom de la variable contenant une copie de la référence par un dollar ‘$’
En conclusion de cet article, nous avons étudié les pointeurs qui sont propres en C et les références que vous pouvez retrouver dans de nombreux langages. Les références sont très utilisées dans le monde de la programmation car elles permettent de travailler sur des quantités de données très grandes sans avoir à copier systématiquement des contenus économisant ainsi du temps processeur et de la mémoire. Leur utilisation va bien au delà de ce qui est décrit dans cet article bien entendu, mais il s’agit ici de bases de programmation.
Dans le prochain article nous allons parler des énumérations et des variables tableaux qui sont très utiles en programmation. En attendant, je vous laisse avec un peu de lecture.
Dans cette série d’articles nous allons voir des bases de programmation. Il est recommandé d’avoir consulté au préalable l’article traitant des données numériques. Les sujets traités seront les variables (types, constantes, tableaux, les pointeurs ou références), les structures de contrôle (boucle, switch, conditions) et les fonctions (déclaration, utilisation). Au delà, les détails propres à chaque langages seront traités dans des articles dédiés à chacun d’entre eux.
Les différents langages traités ici, ne pas du même niveau. En effet, le langage C est un langage bas niveau qui doit être compilé (comprendre transformé) en instruction machine lui donnant ainsi une rapidité d’exécution sans pareil. Les autres langages (Perl, PHP et Javascript) sont pour leur part des langages dits de haut niveau. Chacune de leur instruction est interprété par un programme appelé interpréteur qui peut être au choix, votre navigateur web pour javascript, ou un programme spécifique au langage dans les cas du Perl et de PHP.
Pour information dans les parties code définies comme ci-dessous, vous trouverez des commentaires aidant à la bonne compréhension des codes. Il seront représentés comme suit:
// Ceci est un commentaire (Javascript, PHP, C)/* Il s'agit également d'un commentaire* Pouvant être rédigé* Sur plusieurs lignes (Javascript, PHP, C) */# C'est un commentaire aussi (Perl, Shell)
Les commentaires sont des chaînes de caractères (mots, phrases) insérés dans du code de manière à ne pas être interprété. Ils n’ont de valeur que pour les programmeurs, lecteurs du code. Un commentaire n’influencera pas le déroulement d’un programme. Il pourra par contre aider un programmeur reprenant le code d’un autre.
Présentation des variables
En programmation, on appelle variable l’association entre un mot clé (nom de variable) et une (ou plusieurs) valeur pouvant être modifiée au fur et à mesure du déroulement du programme.
Pour ceux qui se sentent déjà perdus, voici un exemple simple en PHP.
<?php// En PHP les noms variables doivent être précédés du symbole $// Je renseigne ici ma variable $nomprenom avec un nouveau contenu$nomprenom='Henry Dupont';// J'utilise ici le contenu de cette variable// La fonction echo permet d'afficher du texte et le contenu (ASCII, affichable) de certaines variables simplesecho"Salutations $nomprenom";?>
Le code ci-dessus affichera: Salutations Henry Dupont
Si la valeur de la variable $nomprenom venait à être modifié, le même morceau de code affichera le nouveau contenu de $nomprenom.
Cela pourrait permettre par exemple de créer des salutations pour une liste de prénom-nom sans avoir à réécrire le code pour chaque cas de figure.
Une variable peut avoir un contenu bien plus complexe qu’un simple texte et c’est ce que nous allons voir ci-dessous.
Les constantes
En opposition avec les variables, on trouve les constantes qui, comme leur nom l’indique ont un contenu qui ne change pas.
Par exemple, PI est une constante, sa valeur ne changera pas au cours de l’exécution d’un programme. (en tout cas pas sans remettre en cause un certain nombre de choses)
Exemple en Javascript
// Définition de la constante PIconstPI=3.14159265359;// Définition de la variable r (pour rayon)r=12;// Utilisation de la constante PI avec la variable rconsole.log('Circonférence d’un cercle de rayon r: '+r+'='+ (2*PI*r);
L’exemple ci-dessus affichera: Circonférence d’un cercle de rayon r: 12 = 75.39822368616001
Exemple en PHP
<?php// Définition de la constante PIdefine("PI",3.14159265359);// Définition de la variable r (pour rayon)$r=12;// Utilisation de la constante PI avec la variable recho"Circonférence d’un cercle de rayon r: $r = ".(2*PI*$r);?>
L’exemple ci-dessus affichera: Circonférence d’un cercle de rayon r: 12 = 75,39822368616
Exemple en C
#include<stdio.h>#include<stdlib.h>/* Pour compiler ce code source:* gcc constante.c -o constante.exe* Pour éxécuter ce programme une fois compilé ./constante.exe (sous UNIX/Linux) ou constante.exe (sous Windows)*//* Définition de la constante PI */#definePI3.14159265359intmain(void){ /* Définition de la variable r (pour rayon) short int r=12; /* Utilisation de la constante PI */printf("Circonférence d’un cercle de rayon r: %d = %f\n", r,(float)(2*PI*r));return EXIT_SUCCESS;}
L’exemple ci-dessus affichera une fois compilé et éxécuté: Circonférence d’un cercle de rayon r: 12 = 75.398224
Exemple en Perl
#!/usr/bin/perluse strict;use warnings;# Définition de la constante PIuse constant PI => 3.14159265359;# En Perl, comme en PHP les noms de variable doivent être précédés du symbole $# Définition de la variable r (pour rayon)my$r=12;# Utilisation de la constante PI avec la variable rprint"Circonférence d'un cercle de rayon r: $r = ".(2*PI*$r)."\n";
L’exemple ci-dessus affichera une fois exécuté: Circonférence d’un cercle de rayon r: 12 = 75.39822368616
Pour une constante il est important que quelqu’un ne puisse pas faire quelque chose comme ça: PI=8.53!!! C’est pour cela que les constantes sont en général définies d’une manière différente des variables.
Typage
Le typage correspond à la définition du type des données à stocker. Il existe différents niveaux de typage dépendants du langage utilisé.
Par exemple on parlera de typage statique un langage bas niveau comme C où le programmeur doit définir à l’avance (début de fonction ou de programme) le type de données qui sera stocké dans la variable (char, int, cf: Article sur les données numériques). Au contraire on parlera plutôt de typage dynamique pour des langages de plus haut niveau (PHP par exemple) qui ne demanderont pas au programmeur de définir à l’avance ses variables ni de spécifier le type des données qui seront stockées.
3 est un nombre. Nombre est un type.
3.1415 est un nombre à virgule. Nombre à virgule est un type.
C est une lettre. Lettre est également un type.
Bonjour est un mot. Mot est aussi un type (en fonction des langages).
-8 est un nombre négatif. Nombre négatif a lui aussi un type pour le représenter.
Déclarez vos variables
Dans l’oeuvre de Douglas Adams Le guide du voyageur intergalactique il est dit que la réponse à la Grande Question sur la Vie, l’Univers et le Reste est 42. Essayons de rentrer le nombre 42 dans une variable et ceci dans différents langages.
En C (typage statique)
/* On précise un type numérique adapté */shortint reponse=42;/* On pourrait également utiliser un type plus large */int reponse=42;/* Ou encore plus petit car le nombre est inférieur à 127 *//* Attention! Dans ce cas de figure le nombre n'est pas stocké sous forme de caractère mais bien sous sa forme numérique *//* Ce qui donne en hexadécimal: 2A *//* Le caractère ASCII associé à 2A est * ce qui vous vous en doutez n'a rien à voir avec le contenu que nous venons d'entrer dans cette variable */char reponse=42;/* Ici il sera stocké sous forme d'une chaîne de caractère ASCII soit 2 caractères de 8 bits chacun *//* Soit en hexadécimal: 34 32 *//* N'étant pas de type numérique, il sera alors impossible de l'utiliser dans des calculs en l'état. */char reponse[]="42";/* B est un caractère donc de type char et sera stocké avec son code ASCII : 42 */char lettre='B';/* Bonjour est un mot, en C un mot est un tableau de caractères (appelé aussi string)* Ce tableau (que nous verrons plus en détails dans un autre article) contiendra respectivement les codes ASCII des lettres* B o n j o u r soit 42 6F 6E 6A 6F 75 72 */char mot[]="Bonjour";
Le langage C est très précis et propose de nombreux types de données pour définir les variables.
En PHP (typage dynamique)
<?php/* PHP déterminera qu'il s'agit d'un numérique et adaptera le type de la variable en conséquence */$reponse=42;// Affiche integer ce qui correspond à un entierechogettype($reponse)/* Si 42 est entouré de double quotes, PHP l’interprétera alors comme une chaîne de caractères, c'est une forme de typage en PHP */$reponse="42";// Affiche string ce qui correspond à une chaîne de caractèresechogettype($reponse)// Toutefois, si on utilise $reponse défini avec les doubles quotes dans un calcul, celui-ci sera alors interprété comme un nombre */echo($reponse+$reponse);// Affichera 84?>
En Perl (typage dynamique)
/* Perl détermine qu'il s'agit d'une valeur numérique */my$reponse=42;/* Perl détermine qu'il s'agit d'une chaîne de caractères */my$reponse="42";// Comme en PHP, utiliser $reponse défini comme une chaîne de caractère dans un calcul interprétera ce dernier comme un nombre.print ($reponse + $reponse); # Affichera 84
Enfin le cas particulier du Javascript
/* Javascript détermine qu'il s'agit d'une valeur numérique */varreponse=42;console.log(typeof(reponse));// Affichera number/* Javascript détermine qu'il s'agit d'une chaîne de caractères */my$reponse="42";console.log(typeof(reponse));// Affichera string// A la différence de Perl de PHP, Javascript traitera un string en tant que tel, même dans un calculconsole.log((reponse+reponse));// Affichera 4242, on parle alors de concaténation (à suivre dans un autre article)
Les signes
Le mot clé unsigned permet de préciser que le type n’est pas signé et ne pourra contenir par conséquent que des valeurs positives allant de 0 à 2x (où x vaut le nombre de bits du type). Un type signé permet lui de contenir des valeurs négatives comme positives allant de -2(x-1) à 2(x-1)-1. Pourquoi la valeur positive est diminuée de 1? C’est simple, la valeur 0 est une valeur qu’il faut prendre en compte dans nos calculs car elle existe bien.
Par exemple, un type unsigned char permet de coder des valeurs allant de 0 à 255 soit 256 valeurs. Dans le cas d’un char signé, on ne peut coder que de 256 valeurs également allant de -128 à 127 ce qui nous fait bien 256 valeurs en comptabilisant le 0. Le signe du nombre contenu utilise 1 bit dont la valeur est soit à 0 indiquant que le nombre est positif, soit à 1 indiquant que le nombre est négatif. Pour mieux comprendre, voici un petit exemple utilisant deux signed char de même valeur avec avec un signe différent. Attention! Cet exemple ne tient pas compte de l’architecture endianness un PC ne codera pas la valeur comme dans l’exemple ci-dessous, mais plutôt 111010012 soit e916 (l’ordre des bits est inversé).
Positions des bits
SIGNE
0
1
2
3
4
5
6
Valeur binaire de 23
0
0
0
1
0
1
1
1
Valeur hexa de 23
1
7
Positions des bits
SIGNE
0
1
2
3
4
5
6
Valeur binaire de -23
1
0
0
1
0
1
1
1
Valeur hexa de -23
9
7
Les flottants
Voici un type dédié au stockage des nombre décimaux.
En C il existe plusieurs types de flottant
/* Le flottant à précision simple */float valeur=12.75;/* Le flottant à précision double */double valeur=3.14159265358979323846264338327950288419716939937510582097494459230781640628620899;
Voici comment les données sont rangées en fonction du type. Une fois encore, ce schéma ne tient pas compte de l’architecture. Garder une lecture de gauche à droite permet de simplifier la présentation de ces types plus complexes..
Les autres langages traités ici (Perl, Javascript et PHP) ne feront pas de différence. Javascript nous répondra number quoi qu’il arrive, PHP stockera décrétera qu’il s’agit d’un double que nous souhaitions stocker 2.75 ou un nombre avec 50 décimales.
Nous venons de balayer dans cet article les variables simples avec la plupart des types de base utilisés en programmation. Il en existe d’autres plus complexes et plus spécifique dont nous étudierons (pour certain) les détails dans d’autres articles à venir.
Liens et références
En attendant le prochain article, si vous souhaitez vous documenter un peu sur le sujet, voici quelques liens intéressants:
Ma documentation préférée reste celle du PHP que je trouve particulièrement bien présentée et facile à comprendre. Pour le reste, je vous souhaite une bonne lecture.
Vous retrouverez les liens et références à la fin de cet article.
1 – Les bits
Le bit est la plus petite unité numérique définissable. Le bit correspond l’état d’un signal électrique (arrêt ou marche). Un bit peut se résumer à un interrupteur contrôlant une ampoule qui est soit en à l’arrêt (0) soit en fonctionnement (1). Seul, il ne représente rien et on ne peut pas définir de donnée plus complexe que OUI ou NON. Pour créer l’informatique il aura été nécessaire de regrouper les bits en blocs nommés octets.
Représentation d’une séquence de bits sous forme de signal électrique La ligne horizontale représente le temps, et la ligne vertical l’état du signal
2 – Les octets
Stockage des octets
Sur les premiers systèmes d’exploitations publics (GECOS créé en 1962 par la General Electric) les octets étaient des assemblages de 6 bits stockés sur des fiches en carton appelées “cartes perforées” et regroupés par “mots” de 36 bits. La première carte perforée a été créée vers 1725 pour automatiser des métiers à tisser.
Plus tard, avec l’apparition du standard ASCII, les octets sont devenus des assemblages de 8 bits.
Un bit pouvant avoir 2 valeurs (0 ou 1), un octet comportant 8 bits permet donc de coder 28 = 2×2×2×2×2×2×2×2 = 256 valeurs (de 0 à 255).
Un octet peut être représenté de différentes manières:
En binaire allant de 00000000 à 11111111
En hexadécimal (base 16) de 00 à FF (aussi écrit: 0x00 à 0xFF)
En décimal non signé de 0 à 255
En décimal signé de -128 à 127
Voici une liste de supports pour stocker nos octets:
Sur des cartes perforées par “mots” de 80 caractères de 8 bits (mais aussi les codes bar ou QR codes)
Sur des puces électroniques PROM – EPROM – EEPROM (cartes SD, ou disques SSD, barettes de mémoire RAM)
Sur des bandes magnétiques, cassettes ou cartouches, puis disquettes (cartouches LTO, cassettes DAT, et aussi sur nos veilles cassettes audio à l’époque des Amstrad et ORIC)
Ces données stockées sous forme de signaux électriques étaient décodées par des modem intégrés à nos vieux ordinateurs
Sur des disques de métal au format binaire proche des cartes perforées (CDROM, DVDROM, BluRay)
Sur des disques magnétiques au format binaire par impulsions électriques (disques dur)
A présent que nous avons défini les octets, nous savons les stocker sur différents types de supports. C’est bien beau tout ça, mais qu’allons nous faire de ces données numériques?
Traitement des octets
Les microprocesseurs ont évolué depuis l’aube de l’informatique et leur aptitude à traiter des mots de plus en plus long et de plus en plus rapidement ont permis aux ordinateurs d’évoluer jusqu’aux capacités époustouflantes qu’on leur connait aujourd’hui. Mais cela n’a pas toujours été ainsi. Aux premières heures de l’informatique grand public, les microprocesseurs ne savaient traiter qu’un nombre de données restreint et pire encore, ils le faisaient beaucoup plus lentement qu’aujourd’hui.
Voici l’évolution de la taille des mots traités par les microprocesseurs (CPU) grand public:
La taille des mots en bits qu’un microprocesseur sait traiter lui permet également de définir des plages d’adresses pour stocker des données en mémoire. Il faut se représenter la mémoire RAM comme un damier avec des coordonnées pour chaque case. Plus le damier est grand, plus vous aurez un nombre de case important et donc vous aurez besoin plus de bits pour définir ce nombre. Si vous rangez vos données dans le damier mais que vous n’êtes pas en mesure de noter les coordonnées où elles sont stockées, comment allez vous les retrouver?
Voici la quantité de mémoire adressable en fonction de la taille du bus mémoire en bits:
8 bits ⇒ 16 Ko (2 puissance 8)
16 bits ⇒ 64 Ko (2 puissance 16)
32 bits ⇒ 4 Go (2 puissance 32)
64 bits ⇒ 16 777 216 To ou 16 Eo (2 puissance 64)
Bien sûr, il existe des astuces de programmation qui permettent d’adresser plus de mémoire que la limite du bus ne le permet. Mais ce sera au détriment des performances.
3 – Les types de données de base
Maintenant, avec les connaissances que nous avons, nous savons traiter et stocker des données…
Oui mais au fait, quoi comme données???
C’est vrai! Comment faire la différence entre des numéros de série et des vraies données numériques utilisées dans des calculs?
En somme, comment différencier des chiffres utilisés dans du texte et des chiffres utilisés pour des calculs? Comment faire comprendre ça à un microprocesseur?
Le standard ASCII nous indique que chaque caractères imprimables (a, B, c, D, 0, 1, 2, @ etc…) correspond à un code (dit code ASCII) numérique lui donnant une position bien définie dans la table du même nom. Ainsi, avec seulement des chiffres, nous sommes capables de stocker du texte et bien d’autres choses encore.
Par exemple: Le nombre 32768 stocké sous forme de caractères nous coûterait 5 caractères ⇒ 6|5|5|3|5 soit en hexadécimal 33 32 37 36 38.
Le même nombre stocké avec un type binaire adapté (short int par exemple) ne coûterait que 2 caractères ⇒ 80 00
Il existe plusieurs types de données en fonction de l’usage qui leur sera réservé (affichage ou calcul, petits nombres ou très grands nombres, nombres à virgule flottante)
Les types de données présentées ci-dessous sont les types de base tels qu’ils sont utilisés par les microprocesseurs (en langage C, les noms changent en fonction des langages, mais le contenu et le stockage restent les mêmes).
(signed) char
Type de donnée: Caractère (character) / Entier signé de faible valeur
Taille: 1 octet (8 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(char)
Une chaîne de caractère est en fait un tableau de caractères comme suit: nombre de caractères × sizeof(char)
Peut contenir: ‘a’ ou ‘z’ ou ‘8’ ou ‘+’
Valeur décimale: de -128 à 127
Valeur hexadécimale: de 00 à FF
Stockage: Non affecté
unsigned char
Type de donnée: Caractère (character) non signé / Entier de faible valeur positive
Taille: 1 octet (8 bits) / caractère en général (ASCII)
En C il est recommandé de calculer la taille avec la fonction sizeof(char)
Peut contenir: ‘a’ ou ‘z’ ou ‘8’ ou ‘+’
Valeur décimale: de 0 à 255
Valeur hexadécimale: de 00 à FF
Stockage: Non affecté
(signed) short int
Type de donnée: Entier numérique
Taille: 2 octets (16 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(short int)
Peut contenir: de -32768 à 32767
Valeur décimale: de 0 à 65535
Valeur hexadécimale: de 00 00 à FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
unsigned short int
Type de donnée: Entier numérique positif
Taille: 2 octets (16 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(short int)
Peut contenir: de 0 à 65535
Valeur décimale: de 0 à 65535
Valeur hexadécimale: de 00 00 à FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
(signed) int (16 bits/32 bits)
Type de donnée: Entier numérique
Taille: 2 octets (16 bits) / 4 octets (32 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(int)
Peut contenir: de -2 147 483 648 à 2 147 483 647
Valeur décimale: de 0 à 4 294 967 295
Valeur hexadécimale: de 00 00 00 00 à FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
unsigned int (16 bits/32 bits)
Type de donnée: Entier numérique positif
Taille: 2 octets (16 bits) / 4 octets (32 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(int)
Peut contenir: de 0 à 4 294 967 295
Valeur décimale: de 0 à 4 294 967 295
Valeur hexadécimale: de 00 00 00 00 à FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
(signed) long int (16 bits/32 bits)
Type de donnée: Entier numérique
Taille: 4 octets (32 bits) / 8 octets (64 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(long int)
Peut contenir: de -9 223 372 036 854 775 808 à -9 223 372 036 854 775 807
Valeur décimale: de 0 à 18 446 744 073 709 551 615
Valeur hexadécimale: de 00 00 00 00 00 00 00 00 à FF FF FF FF FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
unsigned lont int (16 bits/32 bits)
Type de donnée: Entier numérique positif
Taille: 4 octets (32 bits) / 8 octets (64 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(long int)
Peut contenir: de 0 à 18 446 744 073 709 551 615
Valeur décimale: de 0 à 18 446 744 073 709 551 615
Valeur hexadécimale: de 00 00 00 00 00 00 00 00 à FF FF FF FF FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
(signed) long long int
Type de donnée: Entier numérique de grande taille
Taille: 8 octets (64 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(long long int)
Peut contenir: de -9 223 372 036 854 775 808 à -9 223 372 036 854 775 807
Valeur décimale: de 0 à 18 446 744 073 709 551 615
Valeur hexadécimale: de 00 00 00 00 00 00 00 00 à FF FF FF FF FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
unsigned long long int
Type de donnée: Entier numérique positif de grande taille
Taille: 8 octets (64 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(long long int)
Peut contenir: de 0 à 18 446 744 073 709 551 615
Valeur décimale: de 0 à 18 446 744 073 709 551 615
Valeur hexadécimale: de 00 00 00 00 00 00 00 00 à FF FF FF FF FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
float
Type de donnée: Flottant numérique à précision simple
Taille: 4 octets (32 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(float)
Peut contenir: de -3.4e-38 à 3.4e38 avec une précision à 7 décimales
Valeur décimale: de 0 à 4 294 967 295
Valeur hexadécimale: de 00 00 00 00 à FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
double
Type de donnée: Flottant numérique à précision double
Taille: 8 octets (64 bits)
En C il est recommandé de calculer la taille avec la fonction sizeof(double)
Peut contenir: de -1.7e-308 à 1.7e308 avec une précision à 15 décimales
Valeur décimale: de 0 à 18 446 744 073 709 551 615
Valeur hexadécimale: de 00 00 00 00 00 00 00 00 à FF FF FF FF FF FF FF FF
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
long double (32 bits / 64 bits)
Type de donnée: Flottant numérique de grande taille à forte précision
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
void * (dépendant de l’architecture)
Type de donnée: Pointeur (adresse mémoire)
Taille: (complètement dépendant de l’architecture)
En C il est recommandé de calculer la taille avec la fonction sizeof(void *)
Peut contenir: Toute la plage adressable par l’architecture
Valeur décimale: (complètement dépendant de l’architecture)
Valeur hexadécimale: (complètement dépendant de l’architecture)
Stockage: Dépendant de l’architecture BIG ENDIAN/LITTLE ENDIAN
4 – L’histoire du petit et du grand indien…
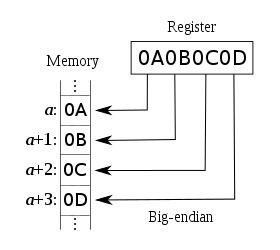
Il existe différents ordres de stockage des données numérique de grande taille (16 bits et au delà) dont les plus connus sont nommés LITTLE ENDIAN, BIG ENDIAN ou encore BI-ENDIAN (plus rare). Pour des raisons de culture, de conception et de logique différentes, les deux principales architectures stockent et traitent les données dans un ordre qui lui est propre.
Processeurs LITTLE-ENDIAN: Intel et compatibles Intel (x86 IA32, IA64 ou amd64)
Le petit boutiste (LITTLE-ENDIAN) range l’octet de poid faible à l’adresse la plus petite
Processeurs BIG-ENDIAN: SPARC, ARM, PowerPC
Le grand boutiste (BIG-ENDIAN) range l’octet de poid fort à l’adresse la plus petite
En résumé, on peut dire que les données sont rangées en mémoire en fonction de l’architecture matérielle qui les traite.
Vous trouverez ci-dessous un petit bout de code en C qui, une fois compilé (avec gcc) et éxécuté, va générer un fichier par type (au sens C du terme) en stockant une valeur à l’intérieur afin de vous donner un aperçu de la manière dont les données numériques sont rangées en mémoire. Le binaire enregistre les données dans des fichiers telles qu’elles sont stockées en mémoire. Je vous recommande de vous équiper d’un éditeur hexadécimal pour comparer les contenus des fichiers (Editeur hexadécimal).
#include<stdio.h>#include<stdlib.h>/* Pour compiler ce code source:* gcc sizeof-types.c -o sizeof-types* Pour éxécuter ce programme une fois compilé* ./sizeof-types (sous UNIX/Linux)* ou* sizeof-types.exe (sous Windows)*/intmain(void) {FILE*fd;charchar_val='c';shortintsint_val=25315;intint_val=-1123315;longintlint_val=-3223372036854775807L;floatfloat_val=3.1415926F;doubledouble_val=3.14159265358979323846264338;void*void_val=(void* ) &int_val;/* Codes couleur pour affichage */charbtitle[]="\033[04;34;43m";charecol[]="\033[0m";charbnom[]="\033[04;33;40m";charbtaille[]="\033[01;33;40m";printf("%sType\t\tTaille\t\tType C%s\n",btitle,ecol);printf("%sEntier court\t%s%d octets\t%sshort int%s\n",bnom,ecol,sizeof(shortint),btaille,ecol);printf("%sEntier\t\t%s%d octets\t%sint%s\n",bnom,ecol,sizeof(int),btaille,ecol);printf("%sEntier long\t%s%d octets\t%slong int%s\n",bnom,ecol,sizeof(longint),btaille,ecol);printf("%sEntier long long\t%s%d octets\t%slong long int%s\n",bnom,ecol,sizeof(longlongint),btaille,ecol);printf("%sFlottant\t%s%d octets\t%sfloat%s\n",bnom,ecol,sizeof(float),btaille,ecol);printf("%sCaractere\t%s%d octets\t%schar%s\n",bnom,ecol,sizeof(char),btaille,ecol);printf("%sSans type\t%s%d octets\t%svoid%s\n",bnom,ecol,sizeof(void),btaille,ecol);printf("%sDouble\t\t%s%d octets\t%sdouble%s\n",bnom,ecol,sizeof(double),btaille,ecol);printf("%sDouble long\t%s%d octets\t%slong double%s\n",bnom,ecol,sizeof(longdouble),btaille,ecol);printf("%sPointeur\t%s%d octets\t%svoid *%s\n",bnom,ecol,sizeof(void*),btaille,ecol);/* Ecriture de données typées sur le disque *//* Lire les fichiers avec un éditeur hexadécimal *//* char */fd=fopen("./char","w");if (fd) {fwrite(&char_val,sizeof(char), (size_t) 1,fd);printf("Le caractère (char) 'c' est écrit dans le fichier './char'\n");fclose(fd);}/* short int */fd=fopen("./short_int","w");if (fd) {fwrite(&sint_val,sizeof(shortint), (size_t) 1,fd);printf("La valeur (short int) 25315 est écrite dans le fichier './short_int'\n");fclose(fd);}/* int */fd=fopen("./int","w");if (fd) {fwrite(&int_val,sizeof(int), (size_t) 1,fd);printf("La valeur (int) -1 123 315 est écrite dans le fichier './int'\n");fclose(fd);}/* long int */fd=fopen("./long_int","w");if (fd) {fwrite(&lint_val,sizeof(longint), (size_t) 1,fd);printf("La valeur (long int) -3 223 372 036 854 775 807 est écrite dans le fichier './long_int'\n");fclose(fd);}/* float */fd=fopen("./float","w");if (fd) {fwrite(&float_val,sizeof(float), (size_t) 1,fd);printf("La valeur (float) 3.1415926 est écrite dans le fichier './float'\n");fclose(fd);}/* double */fd=fopen("./double","w");if (fd) {fwrite(&double_val,sizeof(double), (size_t) 1,fd);printf("La valeur (double) 3.14159265358979323846264338 est écrite dans le fichier './double'\n");fclose(fd);}/* void * */fd=fopen("./void","w");if (fd) {fwrite(&void_val,sizeof(void*), (size_t) 1,fd);printf("Le pointeur (void *) %p est écrit dans le fichier './pointer'\n", (void*) void_val);fclose(fd);}returnEXIT_SUCCESS;}
J’ai exécuté ce code sur mon PC actuel (CPU Intel Quad Core 64 Bits) ainsi que sur ma vieille station SUN Ultra Sparc 64 bits elle aussi et je vous ai préparé un petit tableau ci-dessous avec les résultats à comparer. La différence saute aux yeux dès que l’on arrive sur des types plus complexes qu’un simple caractère.
Type de base
Valeur
LITTLE-ENDIAN (mon PC)
BIG-ENDIAN (ma vieille station Sun Ultra SPARC 64)
char (8 bits / 1 octet)
c
63
63
short int (16 bits)
25315
E3 62
62 E3
int (32 bits)
-1123315
0D DC EE FF
FF EE DC 0D
float (32 bits)
3.1415926
DA 0F 49 40
40 49 0F DA
long int (64 bits)
-3223372036854775807
01 00 58 EC 35 48 44 D3
D3 44 48 35 EC 58 00 01
double (64 bits)
PI (26 décimales)
40 09 21 FB 54 44 2D 18
18 2D 44 54 FB 21 09 40
Liens et références
Cet article n’a pas pour vocation d’être complet. Si vous souhaitez en savoir plus, voici une liste d’articles traitant en détails des différents sujets soulevés dans cet article. Bonne lecture!
Pour offrir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations des appareils. Le fait de consentir à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou les ID uniques sur ce site. Le fait de ne pas consentir ou de retirer son consentement peut avoir un effet négatif sur certaines caractéristiques et fonctions.
Fonctionnel
Toujours activé
L’accès ou le stockage technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
L’accès ou le stockage technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’internaute.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
L’accès ou le stockage technique est nécessaire pour créer des profils d’internautes afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.